OpenStack云第一天
OpenStack是一个美国国家航空航天局和Rackspace合作研发的,以Apache许可证授权,并且是一个自由软件和开放源代码项目。
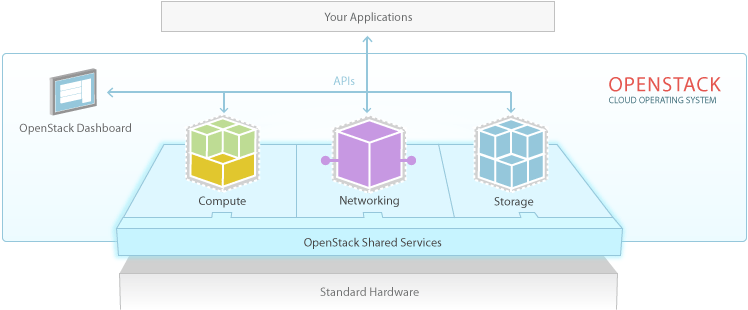
OpenStack是一个云平台管理的项目,这个项目由几个主要的组件组合起来完成一些具体的工作。
OpenStack作为基础设施即服务(简称IaaS)资源的通用前端。OpenStack项目的首要任务是简化云的部署过程并为其带来良好的可扩展性。
1. 关于OpenStack
OpenStack是通过数据中心控制大量的计算,存储与网络资源的云操作系统,管理员通过控制台进行所有的管理,通过Web接口为授权用户提供资源。
接下来我们分别了解一下compute(计算),storage(存储),networking(网络)与dashborad(控制台)。
2. OpenStack Compute
OpenStack Compute提供与管理大量网络虚拟机实例。
OpenStack云操作系统允许企业和服务供应商通过提供与管理大量网络虚拟机来定制灵活的计算资源,你可以开发自己的云应用程序并通过APIs访问这些计算资源,或是管理员简单地通过Web接口访问。计算架构被设计与标准硬件之上。
架构灵活
OpenStack为用户设计自己的云提供了足够的灵活性,OpenStack不需要专门的硬件与软件,并且可以与传统的系统或第三方技术相结合。它被设计用来自动化管理计算资源群组并可以与大多数虚拟化技术协同工作,比如HPC。
在虚拟化环境中,管理员经常会使用一个或多个hypervisor来部署OpenStack Compute。KVM和XenServer就是hypervisor非常流行的选择,建议大多数人选择这种解决方案。如果用户需要减小虚拟化开销来达到 更高的效果与性能的话,Linux容器技术LXC也是被支持的一种解决方案。另外对于不同的hypervisor,OpenStack支持ARM或其他替 换架构。
使用案例:
服务提供商可以提供IaaS给客户
IT部门可以为公司或项目组提供云服务
配合hadoop之类的工具进行大数据运算
矩阵运算,满足web与应用程序从高到低的不同需求
高性能运算处理大量、集中的工作负载
3. OpenStack Storage
OpenStack Storage为服务器或应用程序提供对象与块存储功能。
除了传统企业级存储技术外,现在很多公司为了满足不同的性能与价格需求,他们需要更多样的存储技术。OpenStack支持对象记忆块存储技术,来满足不同的开发需求。
对象存储是性价比很高、可扩展的存储技术。它为我们提供了完全分布式的,可通过API访问的存储平台,这种存储平台可以直接整合到应用中去,或是用 来备份,打包与保留数据。块存储为外部存储提供对计算实例公开并与之连接,可与企业存储平台更好的集成提供更高的性能,如NetApp,Nexenta或 SolidFire。
对象存储功能
OpenStack提供了冗余、可扩展的对象存储,满足云计算存储PE级别数据的要求。
对象存储不是传统的分解系统,它是用来存储像虚拟机镜像,图片,邮件,打包或备份之类的静态数据。没有主控点使得对象存储可以提供更好的扩展性、冗余性和巩固性。
对象与文件在数据中心服务器中被写入到多个磁盘中,通过OpenStack软件确保数据的响应与完整性。
可以简单地通过添加服务器横向扩展云存储。当服务器或磁盘损坏时,OpenStack会从云中的其他活动节点响应数据请求。由于OpenStack通过软件确保数据的响应与分布,你可以用便宜的磁盘与服务器来替代昂贵的设备。
对象存储功能
OpenStack仍然为计算实例提供块级别存储设备。
块存储系统负责管理服务器块设备的创建、添加与删除。块存储卷完全整合于OpenStack Compute并且在控制面板中云用户可以管理他们自己的存储。
使用Linux存储服务器,这种统一的存储结构被大多数存储平台所支持包括Ceph,NetApp,Nexenta以及SolidFire。
块存储适合于对性能敏感的解决方案,如存储数据库、可扩展的文件系统,或为服务器提供原始数据块访问的存储。
快照管理为块存储提供了强大的数据备份功能。快照可以用来还原或创建一个新的块存储卷。
4. OpenStack Networking
OpenStack Networking:可插入的、可扩展的、通过API驱动的网络与IP网络系统。
如今数据中心的网络所包含的设备比以往任何时候否多,网络设备、存储设备、安全设备更进一步划分为虚拟机与虚拟网络。IP地址、路由配置与安全策略 会快速地增长至百万级别。传统的网络管理技术不再适合与下一代网络的扩展性以及自动管理属性。与此同时用户则希望获得更多的控制以及快速服务的灵活性。
OpenStack Networking是一个可插入、可扩展并使用API驱动的网络与IP地址管理系统,像其他云操作系统一样,它可以被管理员或用户用来提升现有数据中心资产的价值。OpenStack Networking确保部署云时网络不会出现瓶颈或某些限制因素,还可以为用户提供真正意义上的自助服务,用户可以通过他们自己的网络配置管理网络。
Networking功能
OpenStack为不同的应用与用户组织提供了足够灵活的网络模型。标准模型包括服务器与通讯分离的平面网络或VLAN。
OpenStack Networking可以通过静态或动态的方式管理IP地址。浮动IP使得与任何计算机资源的通讯可以被动态地重新路由,即允许你在维护设备或设备损坏时重定向通讯流量。
用户可以创建自己的网络,进行通讯控制以及连接服务器与设备。
可插入式架构设计让用户可以从厂商那里获得高级网络服务功能。
管理员可以使用像OpenFlow这样的SDN技术(software-defined networking)
OpenStack Networking的可扩展架构设计可以附加其他网络服务,如入侵检测,负载均衡,防火墙以及VPN等技术。
5. Dashboard
OpenStack dashboard为管理员与用户提供了图形接口的访问方式,基于云的自动化资源。它的可扩展性设计使得加载第三方产品与服务非常容易,比如计费、监控以及额外的管理工具。对于那些想要使用它的服务供应商以及其他的商业厂商而言,控制面板同样很具有吸引力。
Dashboard是与OpenStack资源交互的一种方式。开发者可以使用OpenStack API或EC2兼容API构建自己的工具去管理我们的资源。
Dashboard功能
Dashboard是允许云管理员和用户控制他们计算、存储与网络等资源的可扩展web应用。
作为一名云管理员,dashboard使你可以了解云环境的整体大小与状态。你可以创建用户与项目,并赋予权利给用户以及设置项目资源限制。
Dashboard在管理员给定的限制内可以自主地提供自己的资源。
6. Shared Services
OpenStack提供了众多的共享服务,这些共享服务分别在 compute,storage,networking三大支柱组件中,使你可以更轻松地部署与操控你的云。这些共享服务包括身份认证,镜像管理和供外部 其他系统与OpenStack组件交互的一个Web集成接口。
身份认证服务
OpenStack提供了用户目录与他们能访问的OpenStack服务之间的映射。在整个云操作系统中它扮演了通用型认证系统,并且它可以与现有的后端目录服务如LDAP集成。它提供了多种格式的认证,包括标准的用户名、密码认证,基于令牌系统以及AWS类型的登录。
另外,在OpenStack云中提供了一个可以查询所有已部署服务的目录列表。用户与第三方工具可以规划他们可以访问哪些资源。
作为管理员,OpenStack可以使你:
集中地配置用户与系统策略
使用基于角色控制(RBAC)的特性创建用户以及定义compute,storage,networking资源的权限
与现有LDAP集成,实现单点登录、统一身份认证功能
作为用户,OpenStack可以使你:
获得一份你可以访问资源的列表
通过API请求或登录web控制台去创建属于自己的资源
镜像服务
OpenStack镜像服务可以用来查找、注册与部署服务器镜像。它提供了对镜像的拷贝、快照以及快速存储功能。
多镜像格式的支持,镜像服务允许上传私有或公钥镜像格式,包括:
Raw
Machine(kernel/ramdisk outside of image)
VHD(Hyper-v)
VDI(VirtualBox)
qcow2(Qemu/KVM)
VMDK(VMware)
7. 路线图
OpenStack致力于开放设计与开发进程。社区基于六个月的开发周期运转。
OpenStack项目列表:
OpenStack Compute(代码名称:Nova)
OpenStack Networking(代码名称:Quantum)
OpenStack Object Storage(代码名称:Swift)
OpenStack Block Storage(代码名称:Cinder)
OpenStack Identity(代码名称:Keystone)
OpenStack Image Service(代码名称:Glance)
OpenStack Dashboard(代码名称:Horizon)
OpenStack云第二天
在OpenStack第一天文档翻译后,丁丁努力坚持每晚抽时间翻译OpenStack官方网站提供的安装与部署指南,本文翻译自官方安装与部署指南的前四章内容,前四章内容主要是对OpenStack整体安装步骤以及设计搭建环境进行概述,并未提及具体安装步骤,但对环境的设计与构思以及安装需求还是需要大家了解的。希望尽快写完第三天文档(安装认证服务)。
目录:
一、安装步骤概述
二、OpenStack术语
三、OpenStack结构
四、安装环境构思
一、走马看花-安装OpenStack预览
OpenStack Compute与Image服务结合就可以通过REST APIs访问虚拟服务器与镜像,Identity服务为OpenStack所有服务提供通用认证服务。如果你需要安装控制面板就必须有Identity服务的支持。OpenStack Object Storage服务不就提供了虚拟镜像的存储方式,更是一种基于云的存储系统,通过REST API我们可以保存、还原对象数据比如镜像或视频等等。我们先从Identity开始然后是Image与Compute服务,同时会有部署对象存储的话题。
主要有这么一些步骤:
1.OpenStack目前支持平台预览:Red Hat Enterprise Linux, Scientific Linux, CentOS, Fedora, Debian, Ubuntu。
2.安装Identity服务。
3.配置Identity服务。
4.安装镜像服务(Glance)。
5.配置镜像服务
6.安装Compute(Nova)。
7.安装环境假设。
8.配置Compute。
9.使用MySQL创建并初始化Compute数据库。
10.添加镜像。
11.安装对象存储(Swift)。
12.安装OpenStack控制面板(Dashboard)。
13.通过控制面板添加密钥对。
14.通过控制面板启动镜像并检验整个安装过程。
Compute与Image安装需求
硬件:OpenStack组件适用于标准的硬件设备。以下为满足Compute、Image、Object Storage服务所需最低配置要求:
数据库:OpenStack Compute需要访问PostgreSQL或MySQL数据库,在安装OpenStack Compute的过程中你需要安装这样的数据库。Object Storage,容器与账户服务需要使用SQLite。
权限:需要使用root或拥有sudo权限的用户去安装OpenStack Compute,Image Service以及Object Storage。
NTP协议:你必须安装一个时间同步程序如NTP,在云环境中服务器节点间保持时间同步非常重要。
Compute网络规划:
为了是管理员了解访问APIs与虚拟机所需网络资源与IP规划,本节将为大家提供网络规划的建议。至少千兆网络是必须的。这里展示一下单个服务器的网络配置。
OpenStack Compute网络可以使用扁平式网络,DHCP以及VLAN,运行nova-network的服务器建议配置双网卡。
管理类网络设计:这个网络用来在云架构中不同服务器直接相互通讯,建议可以容纳255台主机的IP规划(CIDR/24)。
公共网络设计:这个网络为外网提供连接使用,互联网用户可以通过这些IP访问云服务。建议设计8个IP。
虚拟网络设计:为虚拟机设计私有IP地址。建议CIDR/24。
安装NTP
保持云中多台主机的时间同步,你需要安装NTP软件,在云环境的多节点中,以下为服务器配置的参考模版。
1.安装软件
$ sudo yum install –y ntp
2.配置服务端:在云控制节点上通过修改ntp.conf配置NTP服务器,然后启动服务。(原文中未设置服务端的具体设置,可google参考相关资料)
$ sudo service ntpd start
$ sudo chkconfig ntpd on
3.配置NTP客户端,是compute节点与云控制节点同步时间,并将以下命令作为计划任务定期执行。
# ntpdate‘服务器IP’
# hwclock -w
二、OpenStack术语
版本名
每一份OpenStack发行版本都有一个版本名称,版本名称按字母顺序增加(如:Diablo的下一个版本是Essex)。这些发行版本也有相应的版本号,但这个版本号不同于OpenStack Compute,OpenStack Object Storage的版本号,以下为版本名称列表:
从Cactus开始,OpenStack修改为六个月的开发周期,Folsom预计在2012年10月发布。
代码名称
每个OpenStack服务有一个代码名称,如镜像服务(Image Service)代码名称为Glance。以下为全部代码名称列表:
OpenStack Compute(代码名称:Nova)
OpenStack Networking(代码名称:Quantum)
OpenStack Object Storage(代码名称:Swift)
OpenStack Block Storage(代码名称:Cinder)
OpenStack Identity(代码名称:Keystone)
OpenStack Image Service(代码名称:Glance)
OpenStack Dashboard(代码名称:Horizon)
代码名称可以用来反应配置文件与命令工具的名称,如:认证服务(Identity Service)的配置文件名称为keystone.conf。
OpenStack服务与Linux服务
在Linux概念中,一个服务(也被称为守护进程)表示运行在后台监听特定端口并响应服务请求的单个程序。而OpenStack服务则表示的是若干Linux服务的集合,一个OpenStack服务需要开启多个Linux服务。如nova-compute与nova-scheduler两个Linux服务负责实施Compute服务。OpenStack还需要依赖与第三方的服务,如数据库(MySQL)以及消息服务(RabbitMQ、Qpid)。
本文档中,我们使用服务来表示底层的Linux服务以及高层的OpenStack服务。你需要通过上下文判断我们所说的服务是OpenStack服务(如:Image)还是Linux服务(如:glance-api)。
存储:对象,块,文件
许多云计算解决方案都要求使用远程存储。而存储的解决方案一般分为三类:对象存储、块存储以及文件存储。
当然有些存储解决方案同时支持多中类型。如:NexentaStor支持块存储与文件存储,GlusterFS支持文件存储与对象存储,Ceph Storage支持对象存储、块存储以及文件存储。
对象存储
在OpenStack中对象存储服务为Swif。
相关的概念:Amazon S3,Rackspace Cloud Files,Ceph Storage。
对于对象存储,所有的文件通过均HTTP接口展现。客户端在用户层上访问对象存储,操作系统并不清楚用户在使用的是远程存储。在OpenStack中,Object Storage提供了对象存储的功能。用户通过HTTP请求访问和修改文件。由于对象存储提供的数据访问接口是一种底层的抽象,所以人们常常会在对象存储的基础上构建基于文件的应用程序。例如,OpenStack Image Server就可以配置使用Object Storage作为后端存储。从对象存储提供HTTP接口后,它的另一个应用是作为静态网站内容(如:图片、多媒体文件等)的内容分发网络(CDN)解决方案。
块存储(SAN)
在OpenStack中提供块存储的是nova-volume。
相关概念:Amazon Elastic Block Store(EBS),Ceph RADOS Block Device(RBD),iSCSI
对于块存储,文件通过计算机底层总线展现如SCSI或ATA接口,这些接口可接入网络。块存储是SAN(存储区域网络)的同义词。客户端通过操作系统设备层访问数据:用户像挂载本地磁盘一样挂载远程设备(Linux中挂载命令为mount)。在OpenStack中,nova-volume服务提供了该项功能。
因为是作为本地磁盘加载,所以终端用户需要创建分区并格式化这些设备。这种设备同时仅可被单个用户挂载使用,所以块存储无法用来在虚拟机实例间作为共享数据之用。
文件存储(NAS)
OpenStack不提供文件存储的支持。
相关概念:NFS,Samba/CIFS,GlusterFS,Dropbox,Google Drive
对应文件存储,文件通过分布式的文件系统协议展现。文件存储与NAS(网络附加存储)是同义词。客户端通过操作系统中的文件系统层面访问数据:用户需要挂载远程文件系统访问数据。文件存储的例子有NFS与GlusterFS。操作系统需要安装适当的软件来访问远程文件系统。
三、OpenStack结构
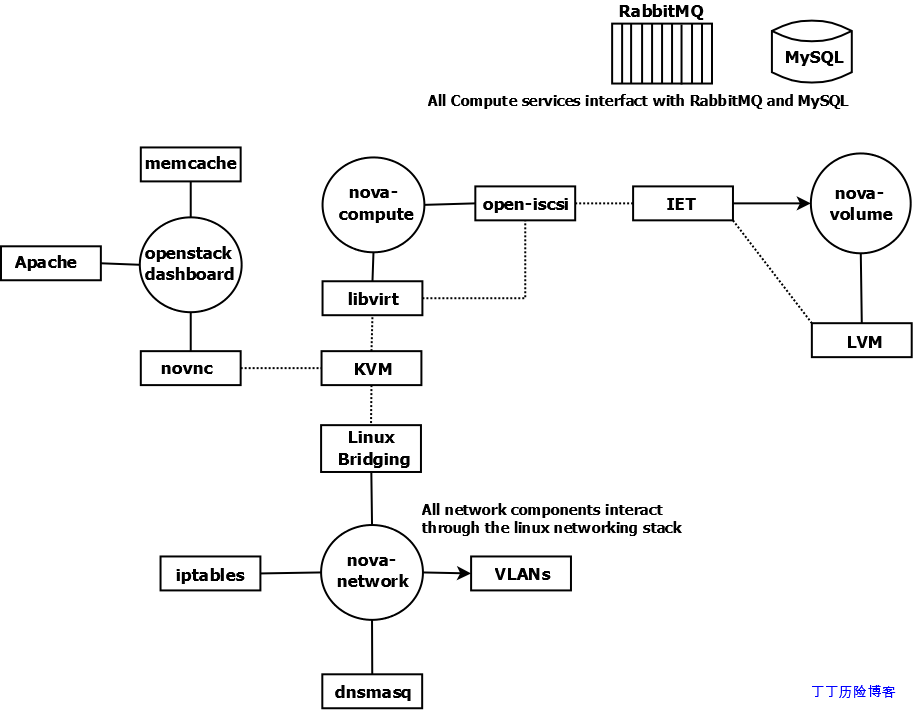
你可以把OpenStack Compute理解为结合现有Linux技术构建云计算环境的工具箱。
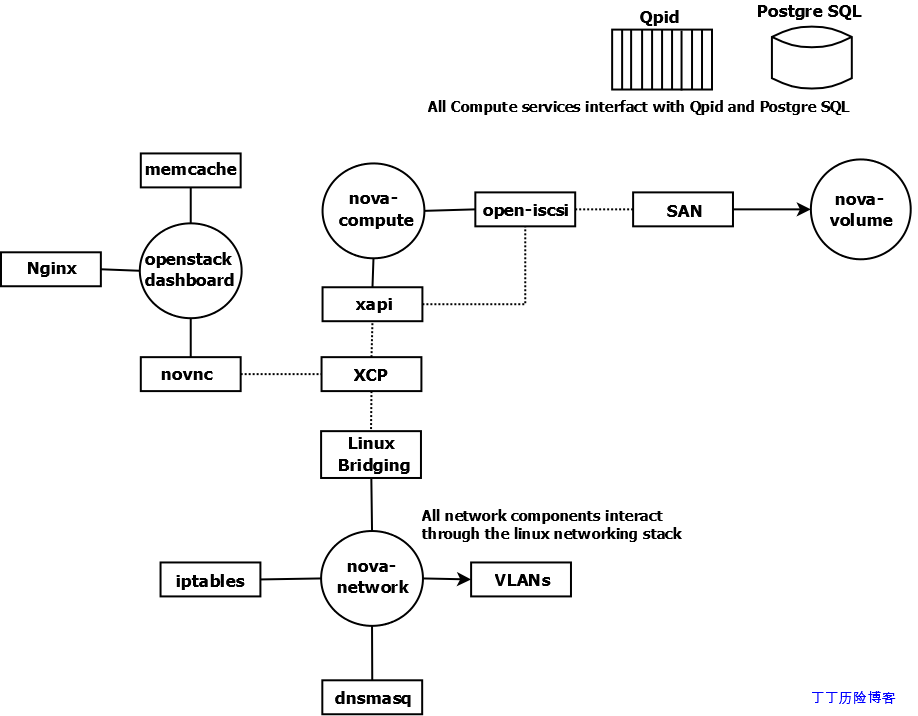
以下我们通过图例说明构建OpenStack Compute云环境的基础技术。圆形表示构成OpenStack Compute的Linux服务,矩形表示外部组件(不属于OpenStack项目),实线表示OpenStack组件与外部组件间的交互,虚线表示外部组件之间的交互。所有组成OpenStack Compute的服务都与后端消息队列(如:RabbitMQ,Qpid)以及后端数据库(如:MySQL)交互,这种交互图中没有连线。同时其他的一些非必须的外部组件技术同样不在该图示中展示,如:nova-api,OpenStack Identity以及OpenStack Image服务。
方案1:
方案2:
如图所示,多数外部组件可以有很多替代产品。
技术与软件:
nova-compute
nova-compute服务依靠虚拟化驱动管理虚拟机。默认驱动为libvirt,可以驱动KVM,但libvirt同样可以驱动其他hypervisor技术。如果你需要使用Xen云平台或XenServer,则Xen虚拟化技术使用单独的驱动。Open-iscsi用来挂载远程块设备,也被称为卷。Open-iscsi将远程设备当作与本地设备一样使用。
nova-network
nova-network服务依赖于一些Linux网络技术,它使用Linux桥接技术来连接虚拟机与物理主机。如果是运行在VLAN网络模式,这些桥设备可以通过Linux VLAN技术相关联。iptables负责安全策略实施与NAT功能。DNSmasq用来快速部署DNS服务器并为虚拟机实例分配IP地址、DNS等网络参数。
在未来的OpenStack发行版本中,nova-network的功能将被独立称为OpenStack的一个独立项目,代码名称为Quantum。
译者再次备注一下,OpenStack提供的手册文档是2012年4月31日,而目前根据OpenStack官网信息显示OpenStack Networking已经是一个独立的项目了。
nova-volume
默认,nova-volume服务使用LVM创建和管理本地卷,并使用IET或tgt通过iSCSI方式发布出去。nova-volume同样可以配置使用其他基于iSCSI的存储技术。
未来的OpenStack发行版本中,nova-volume的功能将被独立为OpenStack项目,代码名称为Cinder。
openstack-dashboard
openstack-dashboard是基于Django的应用程序,它默认运行在Apache Web服务器上。你可以使用memcache来改善它的性能。一个基于web的VNC客户端-novnc,使用novnc连接VNC控制台与KVM实例连接。
四、安装环境构思
OpenStack Compute有大量的配置选项,为了简化本安装指南,我们对需要部署的环境做了一些假设。
- 你已经有了一些安装有Fedora17,RHEL6.2,Scientific Linux6.1或CentOS6发行版的compute节点。备注OpenStack同样支持Ubuntu,但本文档不做说明。
- 你已经选定了一台作为云控制节点,它将除nova-compute外的所有服务(RabbitMQ,MySQL,Identity,Image,nova-api,nova-network,nova-scheduler,nova-volume)。
- 云控制器的磁盘分区使用的是LVM。
- 你的云控制器有一个LVM卷组(VG)名为”nova-volumes”共VM使用,你可以安装系统的使用创建,也可以在安装nova服务前使用剩余空间创建。
- 确保你的主机名可以被正确的解析,另外如果你使用RabbitMQ作为后端消息队列或许会遇到些麻烦,Fedora默认使用Qpid作为消息队列。
- 192.168.206.130是主机上eth0网卡的主IP地址。
- 192.168.100.0/24作为虚拟主机的网络范围,通过桥接br100连接宿主主机。
- FlatDHCP with a single network interface.
- 使用KVM或Xen(XenServer or XCP)作为hypervisor。
- 在RHEL上启用EPEL软件仓库,方法: $ sudo rpm -Uvhhttp://download.fedoraproject.org/pub/epel/6/i386/epelrelease-6-5.noarch.rpm
OpenStack云第三天
部署OpenStack Identity服务。
继OpenStack云第二天,本文翻译自OpenStack安装与部署指南第五章内容,内容主要是安装OpenStack Identity Service(身份认证服务) 。OpenStack Identity服务负责管理用户与客户,项目以及提供为其他OpenStack组件提供通用身份认证系统。
目录:
一、基本概念
二、安装与配置Identity服务
三、验证
一、基本概念身份认证服务包括两个主要功能:
用户管理:时时跟踪用户以及用户被赋予了什么权限。
服务编录:提供一份可用服务的目录并可以定位这些服务的API。
1.1 用户管理Identity用户管理包括三个主要概念:
- 用户(Users)
- 租户(Tenants)
- 角色(Roles)
用户表示拥有用户名,密码,邮箱等帐号信息的自然人。这里给出创建用户名为”alice”的用户:
$ keystone user-create –name=alice –pass=mypassword123
–mail=alice@example.com租户可以被理解为一个项目,团队或组织。你必须指定一个相应的租户(tenant)才可以申请OpenStack服务,例如你指定以某租户申请Compute服务来查询当前运行的实例列表,则你将收到的是该租户的运行实例列表。这里是创建一个名为”acme”租户的例子:
$ keystone tenant-create –name=acme
注意事项:由于在早期的版本中使用项目术语来表示租户,所以有些命令行工具使用–project_id替代–tenant_id给客户分配一个ID号。
角色代表特定的租户中的用户用户操作权限,可以使用如下命令创建角色:
$ keystone role-create –name=compute-user
译者批注:你可以理解租户为那些使用你云环境的客户,这些客户可以是一个项目组、工作组、公司,这些客户中会建立不同的帐号(用户)及其对应的权限(角色).
Identity服务将用户与租户及角色结合在一起,继续刚才的例子,我们也许希望在acme租户中为alice用户分配compute-user角色。
$ keystone user-list
- +———————————+———-+——+——-+
- |id | enabled | email | name |
- +———————————-+———-+——+——-+
- | 96a6ebba0d4c441887aceaeced892585 | True | … | alice |
- +———————————-+———-+——+——-+
$ keystone role-list
- +———————————-+——————+
- |id | name |
- +———————————-+——————+
- | f8dd5a2e4dc64a41b96add562d9a764e | compute-user |
- +———————————-+——————+
$ keystone tenant-list
- +———————————-+——-+———-+
- | id | name | enabled |
- +———————————-+——-+———-+
- | 2395953419144b67955ac4bab96b8fd2 | acme | True |
- +———————————-+——-+———-+
$ keystone user-role-add \
–user=96a6ebba0d4c441887aceaeced892585 \
–role=f8dd5a2e4dc64a41b96add562d9a764e \
–tenant_id=2395953419144b67955ac4bab96b8fd2一个用户可以在不同的租户中被分配不同的角色,例如Alice也可以在Cyberdyne租户中用户admin角色。一个用户也可以在同一个租户中分配多个角色。
/etc/[服务代码名称]/policy.json控制着哪些用户可以拥有什么样的服务,如:/etc/nova/policy.json定义了Compute服务的访问策略,/etc/glance/policy.json定义Image服务的访问策略,以及/etc/keystone/policy.json定义Identity服务的访问策略。
Compute,Identity,Image服务的默认policy.json文件仅识别admin角色:所有的操作无需admin角色即可被租户中拥有任何角色的用户均可以访问。
如果你希望限制用户在Compute服务中所执行的操作,你需要在Identity服务中创建一个角色并修改/etc/nova/policy.json,实现仅提供该角色才可以执行Compute操作。
实例,以下在/etc/nova/policy.json中的配置设定卷创建的操作对用户无任何限制,在租户中的用户用户任何角色均可以创建卷。
“volume:create”: [],如果你需要仅拥有compute-user角色的用户才可以创建卷,你就需要添加一行”role:compute-user”,具体配置如下:
“volume:create”: ["role:compute-user"],
如我们需要对所有Compute服务的请求均需要指定的角色,你的配置文件应该作类似于如下这样的配置:
- {
- “admin_or_owner”: [["role:admin"], ["project_id:%(project_id)s"]],
- “default”: [["rule:admin_or_owner"]],
- “compute:create”: ["role":"compute-user"],
- “compute:create:attach_network”: ["role":"compute-user"],
- “compute:create:attach_volume”: ["role":"compute-user"],
- “compute:get_all”: ["role":"compute-user"],
- “admin_api”: [["role:admin"]],
- “compute_extension:accounts”: [["rule:admin_api"]],
- “compute_extension:admin_actions”: [["rule:admin_api"]],
- “compute_extension:admin_actions:pause”: [["rule:admin_or_owner"]],
- “compute_extension:admin_actions:unpause”: [["rule:admin_or_owner"]],
- “compute_extension:admin_actions:suspend”: [["rule:admin_or_owner"]],
- “compute_extension:admin_actions:resume”: [["rule:admin_or_owner"]],
- “compute_extension:admin_actions:lock”: [["rule:admin_api"]],
- “compute_extension:admin_actions:unlock”: [["rule:admin_api"]],
- “compute_extension:admin_actions:resetNetwork”: [["rule:admin_api"]],
- “compute_extension:admin_actions:injectNetworkInfo”: [["rule:admin_api"]],
- “compute_extension:admin_actions:createBackup”: [["rule:admin_or_owner"]],
- “compute_extension:admin_actions:migrateLive”: [["rule:admin_api"]],
- “compute_extension:admin_actions:migrate”: [["rule:admin_api"]],
- “compute_extension:aggregates”: [["rule:admin_api"]],
- “compute_extension:certificates”: ["role":"compute-user"],
- “compute_extension:cloudpipe”: [["rule:admin_api"]],
- “compute_extension:console_output”: ["role":"compute-user"],
- “compute_extension:consoles”: ["role":"compute-user"],
- “compute_extension:createserverext”: ["role":"compute-user"],
- “compute_extension:deferred_delete”: ["role":"compute-user"],
- “compute_extension:disk_config”: ["role":"compute-user"],
- “compute_extension:extended_server_attributes”: [["rule:admin_api"]],
- “compute_extension:extended_status”: ["role":"compute-user"],
- “compute_extension:flavorextradata”: ["role":"compute-user"],
- “compute_extension:flavorextraspecs”: ["role":"compute-user"],
- “compute_extension:flavormanage”: [["rule:admin_api"]],
- “compute_extension:floating_ip_dns”: ["role":"compute-user"],
- “compute_extension:floating_ip_pools”: ["role":"compute-user"],
- “compute_extension:floating_ips”: ["role":"compute-user"],
- “compute_extension:hosts”: [["rule:admin_api"]],
- “compute_extension:keypairs”: ["role":"compute-user"],
- “compute_extension:multinic”: ["role":"compute-user"],
- “compute_extension:networks”: [["rule:admin_api"]],
- “compute_extension:quotas”: ["role":"compute-user"],
- “compute_extension:rescue”: ["role":"compute-user"],
- “compute_extension:security_groups”: ["role":"compute-user"],
- “compute_extension:server_action_list”: [["rule:admin_api"]],
- “compute_extension:server_diagnostics”: [["rule:admin_api"]],
- “compute_extension:simple_tenant_usage:show”: [["rule:admin_or_owner"]],
- “compute_extension:simple_tenant_usage:list”: [["rule:admin_api"]],
- “compute_extension:users”: [["rule:admin_api"]],
- “compute_extension:virtual_interfaces”: ["role":"compute-user"],
- “compute_extension:virtual_storage_arrays”: ["role":"compute-user"],
- “compute_extension:volumes”: ["role":"compute-user"],
- “compute_extension:volumetypes”: ["role":"compute-user"],
- “volume:create”: ["role":"compute-user"],
- “volume:get_all”: ["role":"compute-user"],
- “volume:get_volume_metadata”: ["role":"compute-user"],
- “volume:get_snapshot”: ["role":"compute-user"],
- “volume:get_all_snapshots”: ["role":"compute-user"],
- “network:get_all_networks”: ["role":"compute-user"],
- “network:get_network”: ["role":"compute-user"],
- “network:delete_network”: ["role":"compute-user"],
- “network:disassociate_network”: ["role":"compute-user"],
- “network:get_vifs_by_instance”: ["role":"compute-user"],
- “network:allocate_for_instance”: ["role":"compute-user"],
- “network:deallocate_for_instance”: ["role":"compute-user"],
- “network:validate_networks”: ["role":"compute-user"],
- “network:get_instance_uuids_by_ip_filter”: ["role":"compute-user"],
- “network:get_floating_ip”: ["role":"compute-user"],
- “network:get_floating_ip_pools”: ["role":"compute-user"],
- “network:get_floating_ip_by_address”: ["role":"compute-user"],
- “network:get_floating_ips_by_project”: ["role":"compute-user"],
- “network:get_floating_ips_by_fixed_address”: ["role":"compute-user"],
- “network:allocate_floating_ip”: ["role":"compute-user"],
- “network:deallocate_floating_ip”: ["role":"compute-user"],
- “network:associate_floating_ip”: ["role":"compute-user"],
- “network:disassociate_floating_ip”: ["role":"compute-user"],
- “network:get_fixed_ip”: ["role":"compute-user"],
- “network:add_fixed_ip_to_instance”: ["role":"compute-user"],
- “network:remove_fixed_ip_from_instance”: ["role":"compute-user"],
- “network:add_network_to_project”: ["role":"compute-user"],
- “network:get_instance_nw_info”: ["role":"compute-user"],
- “network:get_dns_domains”: ["role":"compute-user"],
- “network:add_dns_entry”: ["role":"compute-user"],
- “network:modify_dns_entry”: ["role":"compute-user"],
- “network:delete_dns_entry”: ["role":"compute-user"],
- “network:get_dns_entries_by_address”: ["role":"compute-user"],
- “network:get_dns_entries_by_name”: ["role":"compute-user"],
- “network:create_private_dns_domain”: ["role":"compute-user"],
- “network:create_public_dns_domain”: ["role":"compute-user"],
- “network:delete_dns_domain”: ["role":"compute-user"]
- }
1.2 服务管理服务管理有两个主要的概念:
服务
终端
Identity服务同时维护着一份与各个服务相同的用户(如:Compute服务有一个对应的用户名nova),以及一个名为service的特殊服务租户。
二、安装与配置Identity服务
2.1.安装Identity服务
你可以安装Identity服务在任何能被其他服务主机访问的服务器上,以root身份运行如下命令: # yum install openstack-utils openstack-keystone 备注:原文档仅提供安装命令,但该安装方式需要设置yum源,以下为个人补充的添加yum源方法,方法来源于Fedora项目。$ sudo rpm -Uvh http://download.fedoraproject.org/pub/epel/6/i386/epel-release-6-7.noarch.rpm 安装后,你需要删除sqlite数据库并修改配置文件将其指向MySQL数据库。这样的配置更容易部署多个Keystone前段指向相同的后端数据库服务器。
删除/var/lib/keystone目录下的keystone.db文件。
备注:据译者亲身实验,使用以上的yum源安装时该文件并不会产生,省去了删除文件的步骤。 配置生产环境的数据库存储来取代默认的目录功能以备份服务及终端数据,这里以MySQL为例。
安装MySQL(需要root权限):
# yum install mysql mysql-server 安装过程中会提示为mysql的root帐号设置密码,根据提示设置密码。
设置Mysql为开机启动进程:
# chkconfig –level 2345 mysqld on
# service mysqld start 以下系列命令将创建一个名为”keystone”的数据库,以及一个名为”keystone”的mysql用户名,该用户拥有访问keystone数据库的所有权限。默认,密码与用户名同名。
在Fedora,RHEL,CentOS系统上,你可以通过openstack-db命令创建Keystone数据库。
$ duso openstack-db –init –service keystone 也可以通过手动的方式创建数据库。
$ mysql -u root -p 根据提示:需要输入mysql root的密码,创建keystone数据库。
mysql> CREATE DATABASE keystone; 接着再创建一个对新建keystone数据库具有完全权限的mysql账户,注意为用户选择安全的密码,方法参考以下命令。
mysql> GRANT ALL ON keystone.* TO ‘keystone’@’%’ IDENTIFIED BY ‘你的密码’; 退出MySQL数据库: mysql> quit
回想以下,我们在OpenStack第二天文档中对云环境的构思中建设云控制节点的IP为192.168.106.130。
现在一个Keystone已经安装完成,你可以通过主配置文件修改配置(/etc/keystone/keystone.conf),以及通过命令行初始化数据。默认Keystone的数据保存在sqlite中,在/etc/keystone/keystone.conf修改如下一行connection定义来改变数据存储位置:
connection = mysql://keystone:[密码]@192.168.206.130/keystone 备注:据译者亲身实验,现在的keystone版本默认就将数据库指向了本机的MySQL数据库。 同时,要确保keystone.conf文件中配置了合适的服务标识符,你可以使用自己的随机字串,像下面这样:
admin_token = 012345SECRET99TOKEN012345 或者通过命令行设置随机字串: $ export ADMIN_TOKEN=$(openssl rand -hex 10)
$ sudo openstack-config –set /etc/keystone/keystone.conf DEFAULT admin_token $ADMIN_TOKEN
译者备注:export ADMIN_TOKEN=$(openssl rand -hex 10)是调用openssl命令产生10位随机字串,并将结果赋予ADMIN_TOKEN全局变量;再通过openstack-config命令修改keystone.conf配置文件就admin_token参数的取值为刚刚定义的全局变量ADMIN_TOKEN的值(10位随机字串)。 下一步,重启keystone服务,并设置为开机启动项。
$ sudo service keystone restart && sudo chkconfig keystone on 译者备注:在新的版本中keystone的启动脚本不是keystone,而是openstack-keystone,所以实际工作中你需要将以上命令修改为sudo service openstack-keystone restart && sudo chkconfig openstack-keystone on 最后初始化新的keystone数据库,需要root权限:
# keystone-manage db_sync 2.2.配置Identity服务 设置租户,用户与角色,你最少需要定义一个租户、用户、角色以通过Identity服务的身份验证与授权获得其他服务。
脚本配置:
在Fedora,RHEL或CentOS系统上,你可以通过运行脚本更新数据。 $ sudo ADMIN_PASSWORD=$OS_PASSWORD SERVICE_PASSWORD=servicepass openstack-keystone-sample-data Keystone项目提供了一份部署客户、用户、角色的bash脚本,样本数据在https://github.com/openstack/keystone/blob/master/tools/sample_data.sh。
译者注:系统命令openstack-keystone-sample-data运行的就是位于/usr/share/openstack-keystone目录下的sample_data.sh脚本。 此外,任何用户pyton工具的分布,都可以通过keystone客户端的API运行keystone-init脚本完成初始化动作。
$ git clone https://github.com/nimbis/keystone-init.git 这个初始化脚本需要使用PyYAML,通过https://github.com/nimbis/keystone-init/blob/master/keystone-init.py页面,你可以看到脚本做了哪些工作。
为你的服务器编辑config.yaml文件中的IP地址,你可以在config.yaml目录下运行以下命令快速替换:
$ sed -i.bak s/192.168.206.130/172.16.150.12/g config.yaml 译者备注:sed将把config.yaml文件中所有的192.168.206.130替换为172.16.150.12,生成一份新的config.yaml,老的文件自动备份为config.yaml.bak。 使用root身份运行脚本:
# ./keystone-init.py config.yaml 手动配置 这里我们可以无需脚本、手动配置这些步骤。首先我们创建一个默认tenant(租户),名字叫openstackDemo。 $ keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0 \
tenant-create \
–name openstackDemo \
–description “Default Tenant” \
–enabled true

创建名为adminUser的默认用户:
$keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0 \
user-create \
–tenant_id b5815b046cfe47bb891a7b64119e7f80 \
–name adminUser \
–pass secretword –enabled true  译者备注:英文原文此处有误,命令创建的是adminUser,结果显示name的值为admin。
译者备注:英文原文此处有误,命令创建的是adminUser,结果显示name的值为admin。 创建默认角色,admin与memberRole
$keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0 \
role-create \
–name admin 
$keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0 \
role-create \
–name memberRole 
通过uesr-role-add命令选项,在openstackDemo租户中为adminUser用户赋予admin的角色。
$ keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0 \
user-role-add \
–user a4c2d43f80a549a19864c89d759bb3fe \
–tenant_id b5815b046cfe47bb891a7b64119e7f80 \
–role e3d9d157cc95410ea45d23bbbc2e5c10 这条命令没有输出。
创建一个服务租户,这个租户中包括我们已知的所有服务的服务目录。
$keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0 \
tenant-create \
–name service \
–description “Service Tenant” \
–enabled true 
在Service租户中创建Glance Service用户,我们将在Keystone服务目录中为所有的服务都添加这样的用户。
$keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0 \
user-create \
–tenant_id eb7e0c10a99446cfa14c244374549e9d \
–name glance \
–pass glance \
–enabled true 
在service租户中为用户glance分配admin的角色。
$keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0 \
user-role-add \
–user 46b2667a7807483d983e0b4037a1623b \
–tenant_id eb7e0c10a99446cfa14c244374549e9d \
–role e3d9d157cc95410ea45d23bbbc2e5c10 这个命令没有输出。
在Service租户中创建一个Nova Service用户:
$keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0 \
user-create \
–tenant_id eb7e0c10a99446cfa14c244374549e9d \
–name nova \
–pass nova \
–enabled true 
在service租户中为nova用户分配admin的角色。
$keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0 \
user-role-add \
–user 54b3776a8707834d983e0b4037b1345c \
–tenant_id eb7e0c10a99446cfa14c244374549e9d \
–role e3d9d157cc95410ea45d23bbbc2e5c10 这条命令没有输出。
在Service租户中创建EC2 Service用户:
$keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0 \
user-create \
–tenant_id eb7e0c10a99446cfa14c244374549e9d \
–name ec2 \
–pass ec2 \
–enabled true 
在service租户中为ec2用户分配admin的角色:
$keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0 \
user-role-add \
–user 32e7668b8707834d983e0b4037b1345c \
–tenant_id eb7e0c10a99446cfa14c244374549e9d \
–role e3d9d157cc95410ea45d23bbbc2e5c10 这条命令没有输出。
在Service租户中创建Object Storage服务用户:
$keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0 \
user-create \
–tenant_id eb7e0c10a99446cfa14c244374549e9d \
–name swift \
–pass swiftpass \
–enabled true 
在service租户中为swift用户分配admin的角色:
$keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0 \
user-role-add \
–user 4346677b8909823e389f0b4037b1246e \
–tenant_id eb7e0c10a99446cfa14c244374549e9d \
–role e3d9d157cc95410ea45d23bbbc2e5c10 这条命令没有输出。
后面我们还需要创建服务的定义。
为了使Keystone内置的S3 API与Swift兼容,请确保在keystone.conf文件中定义一个新的过滤器并启用:
定义过滤:
[filter:s3_extension]
paste.filter_factory = keystone.contrib.s3:S3Extension.factory 更新admin_api管道:
将
[pipeline:admin_api]
pipeline = token_auth admin_token_auth xml_body json_body debug ec2_extension crud_extension admin_service 更改为:
[pipeline:admin_api]
pipeline = token_auth admin_token_auth xml_body json_body debug ec2_extension s3_extension crud_extension admin_service 2.3.定义服务 Keystone还担任着服务编录的角色,为其他的OpenStack系统指定哪里有相关的API终端位置。尤其是OpenStack的控制面板(Dashborad)更需要这个编录的服务。 译者备注:Keystone的服务编录类似于注册表,在这里我们把OpenStack所有服务的endpoint(终端)写入服务编录中,服务之间的调用需要经过Keystone的验证,并通过这个服务编录找到目标服务的终端(endpoint)位置。 使用keystone定义服务的方式有两种:
使用模版文件的方式因为其比较简单,但除非是像DevStack这样的开发环境否则我们并不推荐使用这种模式。使用模版文件不支持通过keystone命令对服务编录执行CRUD操作,但不妨碍你使用service-list命令。而后端数据库则是一种更可靠的、高可用、提供数据冗余的方式。这节我们将描述如何使用后端数据库架构服务编录,你需要将/etc/keystone/keystone.conf文件中的[catalog]选项修改为如下这种配置:
[catalog]
driver = keystone.catalog.backends.sql.Catalog Keystone服务编录条目的要素 对于目录中的每个服务条目,你都需要执行两个keystone操作:
1).使用keystone service-create命令为服务创建数据库条目,命令选项如下:
–name 服务名称(如:nova,ec2,glance,keystone)
–type 服务类型(如:compute,ec2,image,idnetity)
–description 服务描述(如:”Nova Compute Servece”)
2).使用keystone endpoint-create命令创建数据库条目,描述客户端如果连接不同类型的服务,即指定各个服务的终端位置,命令选项如下:
–region 你为OpenStack云取的区域名称(如:RegionOne)
–service_id 通过keystone service-create命令返回的服务ID(如:935fd37b6fa74b2f9fba6d907fa95825)
–publicurl 服务终端(endpoint)对公网提供的URL(如:http://192.168.206.130:9292/v1或http://192.168.202.130:8774/v2%(tenat_id)s)
–internalurl 服务终端对内提供的URL(典型案例是使用与publicurl相同的值)
–adminurl 提供服务管理界面的URL
Keystone允许URL使用变量,这些变量在运行期间会自动替换为正确的,例如使用类似于tenant_id这样的变量。你可以使用%(变量名)或$(变量名)标识正在使用变量。
创建keystone服务与服务终端(service endpoints) 这里我们会定义服务及其终端。 定义Identity服务:
$ keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0/ \
service-create \
–name=keystone \
–type=identity \
–description=”Keystone Identity Service” 
$ keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0/ \
endpoint-create \
–region RegionOne \
–service_id=15c11a23667e427e91bc31335b45f4bd \
–publicurl=http://192.168.206.130:5000/v2.0 \
–internalurl=http://192.168.206.130:5000/v2.0 \
–adminurl=http://192.168.206.130:35357/v2.0 定义Compute服务,需要为不同的租户(tenant)需要独立的endpoint,这里我们使用上节创建的service租户(tenant)。 $ keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0/ \
service-create \
–name=nova \
–type=compute \
–description=”Nova Compute Service”  $ keystone –token 012345SECRET99TOKEN012345 \
$ keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0/ \
endpoint-create \
–region RegionOne \
–service_id=abc0f03c02904c24abdcc3b7910e2eed \
–publicurl=’http://192.168.206.130:8774/v2/%(tenant_id)s’ \
–internalurl=’http://192.168.206.130:8774/v2/%(tenant_id)s’ \
–adminurl=’http://192.168.206.130:8774/v2/%(tenant_id)s’
 定义卷(Volume)服务,不同的tenant需要独立的endpoint: $ keystone –token 012345SECRET99TOKEN012345 \
定义卷(Volume)服务,不同的tenant需要独立的endpoint: $ keystone –token 012345SECRET99TOKEN012345 \
–endpoint http://192.168.206.130:35357/v2.0/ \
service-create \
–name=volume \
–type=volume \
–description=”Nova Volume Service”

三、验证
安装curl,一个运行REST API请求的命令行工具,同时还需要安装openssl,通过yum安装可以解决依赖包问题:
# yum install curl openssl 你可以运行如下命令,确保你的Identity服务可以正常工作:
curl -d ‘{“auth”: {“tenantName”: “adminTenant”, “passwordCredentials”:{“username”: “adminUser”, “password”: “secretword”}}}’ \
-H “Content-type:application/json” http://192.168.206.130:35357/v2.0/tokens | python -mjson.tool 作为adminUser用户,你将收到如下响应: {
“access”: {
“serviceCatalog”: {},
“token”: {
“expires”: “2012-04-12T00:40:12Z”,
“id”: “cec68088d08747639c682ee5228106d1″
},
“user”: {
“id”: “6b0141904f09480d810a5949d79ea0f3″,
“name”: “adminUser”,
“roles”: [],
“roles_links”: [],
“username”: “adminUser”
}
}
} 或者你可以运行以下命令: curl -d ‘{“auth”: {“tenantName”: “openstackDemo”, “passwordCredentials”:{“username”: “adminUser”, “password”: “secretword”}}}’ \
-H “Content-type:application/json” http://192.168.206.130:35357/v2.0/tokens | python -mjson.tool 你会收到类似于如下的信息: {
“access”: {
“serviceCatalog”: {},
“token”: {
“expires”: “2012-04-12T00:41:21Z”,
“id”: “a220bfdf313b404fa5e063fcc7cc1f3e”,
“tenant”: {
“description”: “Default Tenant”,
“enabled”: true,
“id”: “50af8cc655c24ada96f73010c96b70a2″,
“name”: “openstackDemo”
}
},
“user”: {
“id”: “6b0141904f09480d810a5949d79ea0f3″,
“name”: “adminUser”,
“roles”: [],
“roles_links”: [],
“username”: “adminUser”
}
}
} 这里另外还有一种快速的方法判断Keystone是否工作正常。首先,需要设置如下环境变量: export ADMIN_TOKEN=012345SECRET99TOKEN012345
export OS_USERNAME=adminUser
export OS_PASSWORD=secretword
export OS_TENANT_NAME=openstackDemo
export OS_AUTH_URL=http://127.0.0.1:5000/v2.0/ 通过输入keystone user-list命令,你可以看到用户列表。
$ keystone user-list

OpenStack云第四天
本文翻译自官方部署指南第六章。部署OpenStack Compute及Image服务。在云环境中OpenStack Compute与Image service协同工作,实现通过REST APIs访问虚拟机及镜像的功能。
目录:
一、安装与配置Image服务
二、配置Hypervisor
三、预设网络
四、部署数据库
五、安装与配置云控制器
一、安装与配置Image Service 1.1 使用root身份,安装Image service $sudo yum install openstack-nova openstack-glance 安装后,你需要删除sqlite数据库文件,然后修改配置指向MySQL数据库。删除/var/lib/glance目录下的glance.sqlite文件。
# rm /var/lib/glance/glance.sqlite 1.2 配置后端镜像(Image)服务数据库 配置后端数据存储。使用MySQL创建一个glance数据库以及glance账户,赋予”glance”账户对glance数据库的所有权限。
运行如下命令,进入MySQL数据库:
$ mysql -u root -p //根据提示输入MySQL管理员密码
创建glance数据库:
mysql> CREATE DATABASE glance; 为新创建的数据库创建MySQL账户并赋予完全控制权限:
mysql> GRANT ALL ON glance.* TO ‘glance’@'%’IDENTIFIED BY ‘你的密码’; 退出数据库:
mysql> quit 修改Glance配置文件
更新/etc/glance/glance-api-paste.ini文件,修改[filter:authtoken]下admin_*的值。
- [filter:authtoken]
- admin_tenant_name = service
- admin_user = glance
- admin_password = glance
确保glance-api管道部分包括authtoken
- [pipeline:glance-api]
- pipeline = versionnegotiation authtoken auth-context apiv1app
在/etc/glance/glance-api.conf文件末尾追加如下内容:
- [paste_deploy]
- flavor = keystone
重启glance-api服务: service glance-api restart
译者备注:重启服务实际应该是: service openstack-glance-api restart 在/etc/glance/glance-registry.conf文件末尾追加如下内容:
- [paste_deploy]
- flavor = keystone
更新/etc/glance/glance-registry-paste.ini文件,修改[filter:authtoken]下admin_*的值:
- [filter:authtoken]
- admin_tenant_name = service
- admin_user = glance
- admin_password = glance
确保glance-registry管道部分包括authtoken:
- [pipeline:glance-registry]
- #pipeline = context registryapp
- # NOTE: use the following pipeline for keystone
- pipeline = authtoken auth-context context registryapp
确保/etc/glance/glance-registry.conf和/etc/glance/glance-scrubber.conf文件数据库指向是MySQL而不是sqlite。
- sql_connection = mysql://glance:yourpassword@192.168.206.130/glance
注意:任何时候在修改完.conf配置文件后,记得重启相应的服务,使新的修改生效。
现在,迁移数据库至MySQL: # glance-manage db_sync 重启glance-registry与glance-api服务:
# service openstack-glance-registry restart
# service openstack-glance-api restart 注意事项:本文档为配置镜像缓存,读者可参考
http://glance.openstack.org获得更多信息。
Image服务排除,可以参考日志文件/var/log/glance/registry.log或/var/log/glance/api.log。
1.3 验证Image Service是否安装成功 你可以使用如下命令获得软件的版本号:
# glance –version Essex版本的挣钱版本号为glance 2012.1
下载测试性镜像文件:
# mkdir /tmp/images
# cd /tmp/images
# wget http://smoser.brickies.net/ubuntu/ttylinux-uec/ttylinux-uec-amd64-12.1_2.6.35-22_1.tar.gz # tar -zxvf ttylinux-uec-amd64-12.1_2.6.35-22_1.tar.gz 上传内核:
# glance –os_username=adminUser –os_password=secretword –os_tenant=openstackDemo \
> –os_auth_url=http://127.0.0.1:5000/v2.0 add name=”tty-linuxkernel” \
> disk_format=aki container_format=aki < ttylinux-uec-amd64-12.1_2.6.35-22_1-vmlinuz Uploading image ‘tty-linux-kernel’
==========================================================================
==============================================================================
=========[100%] 41.8M/s, ETA 0h 0m 0s
Added new image with ID: 599907ff-296d-4042-a671-d015e34317d2
上传initrd文件:
# glance –os_username=adminUser –os_password=secretword \
>–os_tenant=openstackDemo –os_auth_url=http://127.0.0.1:5000/v2.0 \
> add name=”tty-linuxOpenStackramdisk” \
> disk_format=ari container_format=ari < ttylinux-uec-amd64-12.1_2.6.35-22_1-loader
Uploading image ‘tty-linux-ramdisk’
==========================================================================
==============================================================================
===[100%] 937.483441K/s, ETA 0h 0m 0s
Added new image with ID: 7d9f0378-1640-4e43-8959-701f248d999d
上传镜像文件:
# glance –os_username=adminUser –os_password=secretword 、
> –os_tenant=openstackDemo –os_auth_url=http://127.0.0.1:5000/v2.0 \
> add name=”tty-linux”disk_format=ami container_format=ami \
> kernel_id=599907ff-296d-4042-a671-d015e34317d2 \
> ramdisk_id=7d9f0378-1640-4e43-8959-701f248d999d < ttylinux-uecamd64-12.1_2.6.35-22_1.imgUploading image ‘tty-linux’
==========================================================================
==============================================================================
===[100%] 118.480514M/s, ETA 0h 0m 0s
Added new image with ID: 21b421e5-44d4-4903-9db0-4f134fdd0793
现在在glance索引中将显示有一个合法的Image。
# glance –os_username=adminUser –os_password=secretword \
> –os_tenant=openstackDemo –os_auth_url=
http://127.0.0.1:5000/v2.0 index

二、配置Hypervisor 对于生产环境,多数人会选择KVM或基于Xen的hypervisor。KVM通过libvirt运行,而Xen则通过XenAPI调用运行。我们默认选择的是KVM,而且它仅需要我们做最少的配置修改。本手册主要讲解KVM。
2.1 KVM KVM是作为Compute默认的hypervisor被配置的。明确的启用KVM,需要在/etc/nova/nova.conf文件中添加如下配置:
- connection_type=libvirt
- libvirt_type=kvm
KVM hypervisor支持如下的虚拟机镜像格式:
- Raw
- QEMU Copy-on-write(qcow2)
- VMware虚拟机格式(vmdk)
本文只要描述如果开启你系统上的KVM,你也需需要以下这些针对特定发行版本的文档作为参考:
2.2 检查你的硬件是否支持虚拟化 使用KVM需要主机CPU支持虚拟化技术(VT)。
如果你在运行Ubuntu,当在BIOS中开启虚拟化功能以及KVM正确的被安装后,可以使用
kvm-ok命令检查你的处理器是否支持VT,如果KVM是开启的,输出应该像这样:
INFO: /dev/kvm exists
KVM acceleration can be used 如果未能开启KVM,输出应该像这样的信息:
INFO: Your CPU does not support KVM extensions
KVM acceleration can NOT be used 如果你的发行版本没有kvm-ok命令,你也可以通过检查处理器标记查看是否支持虚拟化技术。对于Intel的处理器标记为vmx,AMD处理器标记为svm。可以通过以下简单命令来判断: # egrep ‘(vmx|svm)’ –color=always /proc/cpuinfo 有些系统 需要你在BIOS中开启virtualization technology(VT),如果你确信自己的处理器支持硬件加速而上面的命令又没有任何输出,你也许需要重启电脑,进入系统BIOS,开启VT选项。
2.3 开启KVM模块 由于KVM是基于内核的虚拟化技术,所以需要确保kvm模块已经被正确加载。模块名称为kvm,还有kvm-intel或kvm-amd。这些模块的加载也许在你安装KVM软件是就已经自动完成了,你可以使用lsmod命令检查它们是否被正确加载,以下是基于Intel处理器的输出结果:
$ lsmod | grep kvmkvm_intel 137721 9
kvm 415459 1 kvm_intel 接下来,我们看看如果你的系统未能自动加载模块时,如果手动为基于Intel或AMD处理器加载相应模块。
如果你的主机是基于Intel的处理器,以root身份运行如下命令加载内核模块:
# modprobe kvm
# modprobe kvm-intel 将以下两行追加至/etc/modules文件,这样模块在重启后依然会被字段加载:
kvm
kvm-intel 如果你的主机是基于AMD的处理器,以root身份运行如下命令加载内核模块:
# modprobe kvm
# modprobe kvm-amd 将以下两行追加至/etc/modules文件,这样模块在重启后依然会被字段加载:
kvm
kvm-amd 2.4 常见故障 尝试开启虚拟机实例时提示ERROR状态,并且在/var/log/nova/nova-compute.log日志中有如下信息:
libvirtError: internal error no supported architecture for os type ‘hvm’ 这表明你的KVM内核模块未被正确加载。
2.5 QEMU 从Compute service架构来看,QEMU hypervisor非常像KVM hypervisor。两者都通过libvirt控制、都支持一样的特性设置,并且KVM所有的虚拟机镜像都与QEMU兼容。两者最大的差别是QEMU不支持原生虚拟化技术(虚拟机直接运行于硬件之上)。
译者备注:虚拟化有原生虚拟化与宿主虚拟化,宿主虚拟化典型代表是VMware Workstation,其运行在一个已经安装好的系统之上。原生虚拟化则可以直接运行与硬件之上。 所以,QEMU性能比KVM稍差些,一般在生产环境部署的较少。
使用QEMU的案例有:
运行于老的硬件平台上
测试环境 启用QEMU的方式如下:
connection_type=libvirt
libvirt_type=qemu QEMU支持与KVM一样的虚拟机镜像格式:
* Raw
* qcow2
* vmdk
译者备注:原文对Xen做了概念性介绍,但无具体配置描述,所以再次省略,感兴趣可以参考xen官方资料http://xen.org/products/xenhyp.html
三、预设网络 文章将介绍如果在但网络接口上配置使用FlatDHCP模式。
首先,设置你的/etc/network/interfaces文件:(译者备注,这里说的是Ubuntu环境)
* eth0:公网IP,网关
* br100:stp off,fd 0
模版如下:
- # The loopback network interface
- auto lo
- iface lo inet loopback
- # The primary network interface
- auto eth0
- iface eth0 inet dhcp
- # Bridge network interface for VM networks
- auto br100
- iface br100 inet static
- address 192.168.100.1
- netmask 255.255.255.0
- bridge_stp off
- bridge_fd 0
还需要安装bridge-utils: sudo apt-get install bridge-utils RHEL配置要求 在/etc/qpidd.conf文件中设置auth=no
设置SELinux模式为permissive:
# sudo setenforce permissive 如果是基于RHEL6.2的系统,使用openstack-config包关闭DHCP release。
# sudo openstack-config –set /etc/nova/nova.conf DEFAULT force_dhcp_release False 如果是基于RHEL6.3的系统,需要安装dnsmasq工具包:
$ sudo yum install dnsmasq-utils 如果你使用的客户机镜像没有单独的分区,要使文件可以注入需要允许libguestfs检查镜像,设置方法如下: $ sudo openstack-config –set /etc/nova/nova.conf DEFAULT libvirt_inject_partition -1
四、在云控制器上配置SQL数据库 通过mysql客户端工具连接MySQL服务器:
$ mysql -u root -p //根据提示输入密码
创建nova数据库:
mysql> CREATE DATABASE nova; 创建MySQL用户并赋予对新建数据库的所有权限:
mysql> GRANT ALL ON nova.* TO ‘nova’@'%’IDENTIFIED BY ‘密码’; 退出数据库:
mysql> quit
五、安装与配置云控制器
安装消息队列服务器,RabbitMQ。当然你也可以选择Apache Qpid,你可以参考官方Compute Administration Manual中的介绍。
# yum -y install rabbitmq-server 安装nova-开头的软件包,相关依赖包会被自动安装。
# yum -y install openstack-nova-compute openstack-nova-volume openstack-nova-novncproxy openstack-nova-api openstack-nova-ajax-console-proxy openstack-nova-cert openstack-nova-consoleauth openstack-nova-doc openstack-nova-scheduler openstack-nova-network 译者备注:原文此处使用的包为nova-compute格式,不包含openstack。 5.1 配置OpenStack Compute 很多Compute服务的配置选项都存放在/etc/nova/nova.conf文件中。这里我们给出了保障运行的最小配置说明。更多配置选项可以参考OpenStack Compute Administration Manual文档。
一般安装软件包会自动设置用户及权限,如果没有自动完成,以下为手动方式设置:
# groupadd nova
# usermod -g nova nova
# chown -R root:nova /etc/nova
# chmod 640 /etc/nova/nova.conf
编辑/etc/nova/nova.conf设置hypervisor,默认hypervisor为kvm,如果你需要使用其他的hypervisor如Xen,请修改libvirt_type=选项。
确保数据库的连接设置:
格式: sql_connection=mysql://[user]:[pass]@[primary IP]/[db name]
示例: sql_connection=mysql://nova:yourpassword@192.168.206.130/nova
在/etc/nova/nova.conf文件中添加以下这些网络设置,你可以在文件中添加注释说明行,方法是建立以#符号开头的行(以#开头的行全为注释行):
- auth_strategy=keystone
- network_manager=nova.network.manager.FlatDHCPManager
- fixed_range=192.168.100.0/24
- flat_network_dhcp_start=192.168.100.2
- public_interface=eth0
- flat_interface=eth0
- flat_network_bridge=br100
以下为nova.conf文件配置的示例:
- [DEFAULT]
- # LOGS/STATE
- verbose=True
- # AUTHENTICATION
- auth_strategy=keystone
- # SCHEDULER
- compute_scheduler_driver=nova.scheduler.filter_scheduler.FilterScheduler
- # VOLUMES
- volume_group=nova-volumes
- volumevolume_name_template=volume-%08x
- iscsi_helper=tgtadm
- # DATABASE
- sql_connection=mysql://nova:yourpassword@192.168.206.130/nova
- # COMPUTE
- libvirt_type=qemu
- connection_type=libvirt
- instanceinstance_name_template=instance-%08x
- api_paste_config=/etc/nova/api-paste.ini
- allow_resize_to_same_host=True
- # APIS
- osapi_compute_extension=nova.api.openstack.compute.contrib.standard_extensions
- ec2_dmz_host=192.168.206.130
- s3_host=192.168.206.130
- # RABBITMQ
- rabbit_host=192.168.206.130
- # GLANCE
- image_service=nova.image.glance.GlanceImageService
- glance_api_servers=192.168.206.130:9292
- # NETWORK
- network_manager=nova.network.manager.FlatDHCPManager
- force_dhcp_release=True
- dhcpbridge_flagfile=/etc/nova/nova.conf
- firewall_driver=nova.virt.libvirt.firewall.IptablesFirewallDriver
- my_ip=192.168.206.130
- public_interface=br100
- vlan_interface=eth0
- flat_network_bridge=br100
- flat_interface=eth0
- fixed_range=10.0.0.0/24
- # NOVNC CONSOLE
- novncproxy_base_url=http://192.168.206.130:6080/vnc_auto.html
- vncserver_proxyclient_address=192.168.206.130
- vncserver_listen=192.168.206.130
你还需要修改api-paste.ini文件,使用keystone作为认证服务器。译者备注:原文档此处无配置说明,原文的附录部分有一个配置文件示例。
重启nova-服务,接着与数据库同步数据:
# for svc in api objectstore compute network volume scheduler cert; \
> do sudo service openstack-nova-$svc start; sudo chkconfig openstack-nova-$svc on; done 检查所有的服务是否启动成功,查看/var/log/nova日志文件是否有错误。
为Compute配置数据库,通过如下命令在后端数据库中创建数据表:
sudo nova-manage db sync 如果你看到任何响应信息,可以查看/var/log/nova/nova-manage.log查看问题所在。没有回应说明命令正确的被执行了。
重启服务:
sudo restart openstack-nova-api
sudo restart openstack-nova-compute
sudo restart openstack-nova-network
sudo restart openstack-nova-scheduler
sudo restart openstack-nova-vncproxy
sudo restart openstack-nova-volume
sudo restart libvirt-bin //RHEL中为libvirtd服务
sudo /etc/init.d/rabbitmq-server restart
5.2 为Compute虚拟机实例创建网络 你必须运行如下命令为虚拟机创建在nova.conf中设定的网络及br100桥接设备。这个例子中我们为虚拟机分配192.168.100.0/24的网络,但你也可以提供为自己的网络。示例中我们我们把这个网络标记为”private”:
# nova-manage network create private –multi_host=T –fixed_range_v4=192.168.100.0/24 \
> –bridge_interface=br100 –num_networks=1 –network_size=256 5.3 验证Compute的安装 你可以使用root身份运行nova-manage命令来确保所有的Compute服务正常运行:
# nova-manage service list 正常的话,你会收到笑脸 : -)的回应而不是X符号的回应,以下为示例:
Binary Host Zone Status State Updated_At
nova-compute myhost nova enabled  2012-04-02 14:06:15
2012-04-02 14:06:15
nova-cert myhost nova enabled 2012-04-02 14:06:16
nova-volume myhost nova enabled 2012-04-02 14:06:14
nova-scheduler myhost nova enabled 2012-04-02 14:06:11
nova-network myhost nova enabled 2012-04-02 14:06:13
nova-consoleauth myhost nova enabled 2012-04-02 14:06:10 你也可以运行nova-manage查看安装软件的版本:
# nova-manage version list Essex版本的Compute版本号是2012.1
2012.1 (2012.1-LOCALBRANCH:LOCALREVISION) 5.4 定义Compute与Image服务的认证 创建nova与glance命令行需要使用的变量,并保存至openrc文件,本文将openrc文件保存至~/creds目录下:
$ mkdir ~/creds
$ nano ~/creds/openrc 在你创建的openrc文件中粘贴以下内容:
export OS_USERNAME=adminUser
export OS_TENANT_NAME=openstackDemo
export OS_PASSWORD=secretword
export OS_AUTH_URL=http://192.168.206.130:5000/v2.0/export OS_REGION_NAME=RegionOne 接着,让这些变量应用到你的系统环境中:
$ source ~/creds/openrc
通过nova客户端命令显示可用镜像验证认证功能是否正常: 
注意你的系统中ID号将会此有所不同。
5.5 安装额外的Compute节点 为了大规模部署Compute,有多种途径可以帮助你在多个节点安装Compute。
你可以安装所有的nova- 软件包及其依赖关系包,或仅安装nova-network与nova-compute组件在你的云控制节点上。你可以在任何地方安装nova- 服务,只要服务可以访问nova.conf并知道消息队列软件(Rabbitmq | Qpid)安装在哪即可。
因为Compute节点需要查询数据库信息,所以nova客户端与MySQL客户端软件包都应该安装在附加Compute节点上。
拷贝nova.conf到所有的附件compute节点。
OpenStack云第五天
安装OpenStack Object Storage
目录:
一、系统需求
二、对象存储架构
三、安装OpenStack Object Storage
四、安装配置存储节点
五、安装与配置代理节点
六、安装验证
一、系统需求
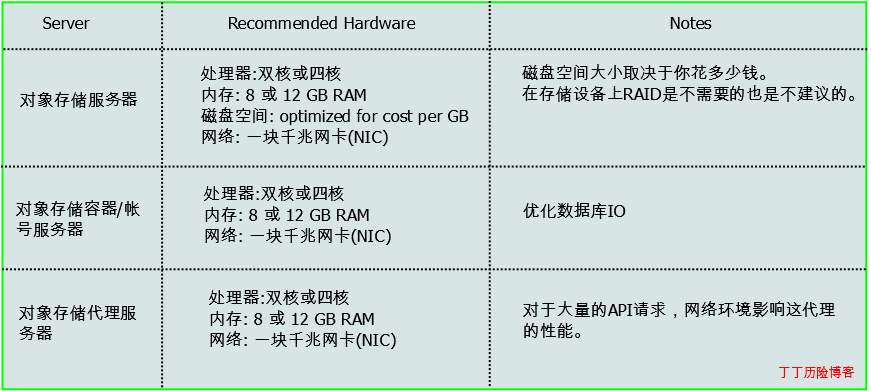
硬件: OpenStack对象存储被设计运行在通用计算机硬件平台上,以下表达为建议硬件配置。
操作系统:OpenStack 对象存储现在可以运行在Ubuntu,RHEL,CentOS或Fedora系统上。
网络:建议千兆网络。为对象存储准备一个额外的网络连接外网的代理服务器。
数据库:OpenStack对象存储,SQLite数据库是OpenStack对象存储容器和帐号管理的进程的一部分。
权限:你可以直接只用root或用户sudo权限的用户执行安装OpenStack对象存储。
网络规划 本文档提供两个网络规划,一个公共网络连接代理服务器,第二个是在存储集群外不可访问的存储网络。
公共网络大小:8IPs(CIDR/29)。
存储网络建议大小:255IPs(CIDR/24)。
二、对象存储架构 节点–运行一个或多个OpenStack对象存储服务的主机。
代理节点–运行代理服务的主机。
认证节点–一个可选的独立于代理服务并运行认证服务的节点。
存储节点–运行用户、容器、对象服务的节点。
环–OpenStack对象存储数据与物理设备之间的映射集合。
为了增加高可用,你有可能会希望添加更多的代理服务以提供性能。
本文档描述的存储节点都是在环中作为独立的区域,建议至少用5个区域。一个区域是相互独立的节点组合。环确保所有的备份数据在不同的区域,下图为最小安装的一种可能:

三、安装OpenStack Object Storage 虽然在开发或测试环境下,你可以安装OpenStack Object Storage在一台服务器上,但多服务器安装可以为你的正式发布产品带来更高的可用性与冗余。
如果你想执行单节点安装,你可以使用Swift All In One 或DevStack。参考
http://swift.openstack.org/development_saio.html 或
http://devstack.org。
开始之前 如果你是在一台新服务器上安装,准备一份系统安装光盘。
本文档演示安装一个使用了如下节点的集群:
* 一个运行swift-proxy-server的代理节点,代理服务器将请求发送至正确的存储节点。
* 五个运行swift-account-server,swift-container-server以及swift-object-server进程的存储节点。
安装步骤 1. 在所有节点安装操作系统,如Ubuntu Server,RHEL,CentOS或Fedora。
2. 安装swift服务以及OpenSSH。
# yum install openstack-swift openstack-swift-proxy openstack-swift-account \
> openstack-swift-container openstack-swift-object memcached 3. 在所有的节点上创建目录:
# mkdir -p /etc/swift
# chown -R swift:swift /etc/swift/ 4. 创建/etc/swift/swift.conf文件
- [swift-hash]
- # random unique string that can never change (DO NOT LOSE)
- swift_hash_path_suffix = fLIbertYgibbitZ
注意:suffix的值为随机字串。
下一步,设置你的存储节点、代理节点以及认证节点,这里我们使用keystone作为通用认证组件。
四、安装与配置存储节点 注意:OpenStack对象存储需要工作在支持XATTRS(扩展属性)的现代文件系统上。我们建议使用XFS文件系统。
1. 安装存储节点包:
# yum install openstack-swift-account openstack-swift-container \
> openstack-swift-object xfsprogs
2. 为所有的设备设置XFS卷:
# fdisk /dev/sdb (创建一个分区)
# mkfs.xfs -i size=1024 /dev/sdb1
# echo “/dev/sdb1 /srv/node/sdb1 xfs noatime,nodiratime,nobarrier,logbufs=8 0 0” >> /etc/fstab
# mkdir -p /srv/node/sdb1
# mount /srv/node/sdb1
# chown -R swift:swift /srv/node 3. 创建/etc/rsyncd.conf
- uid = swift
- gid = swift
- log file = /var/log/rsyncd.log
- pid file = /var/run/rsyncd.pid
- address = <STORAGE_LOCAL_NET_IP>
- [account]
- max connections = 2
- path = /srv/node/
- read only = false
- lock file = /var/lock/account.lock
- [container]
- max connections = 2
- path = /srv/node/
- read only = false
- lock file = /var/lock/container.lock
- [object]
- max connections = 2
- path = /srv/node/
- read only = false
- lock file = /var/lock/object.lock
4. 编辑/etc/default/rsync:
- RSYNC_ENABLE = true //此处为Ubuntu环境,设置开机启动。如CentOS请使用chkconfig
5. 开启rsync进程:
# service rsync start 6. 创建/etc/swift/account-server.conf文件
- [DEFAULT]
- bind_ip = <STORAGE_LOCAL_NET_IP>
- workers = 2
- [pipeline:main]
- pipeline = account-server
- [app:account-server]
- use = egg:swift#account
- [account-replicator]
- [account-auditor]
- [account-reaper]
7. 创建/etc/swift/container-server.conf
- [DEFAULT]
- bind_ip = <STORAGE_LOCAL_NET_IP>
- workers = 2
- [pipeline:main]
- pipeline = container-server
- [app:container-server]
- use = egg:swift#container
- [container-replicator]
- [container-updater]
- [container-auditor]
8. 创建/etc/swift/object-server.conf
- [DEFAULT]
- bind_ip = <STORAGE_LOCAL_NET_IP>
- workers = 2
- [pipeline:main]
- pipeline = object-server
- [app:object-server]
- use = egg:swift#object
- [object-replicator]
- [object-updater]
- [object-auditor]
- [object-expirer]
译者备注:经由译者实验证明,软件安装完成后在/etc/swift目录下,会自动生成account-server,container-server等目录,以上配置文件也可以分别放置在对应的目录下。 9. 开启storage服务:
swift-init object-server start
swift-init object-replicator start
swift-init object-updater start
swift-init object-auditor start
swift-init container-server start
swift-init container-replicator start
swift-init container-updater start
swift-init container-auditor start
swift-init account-server start
swift-init account-replicator start
swift-init account-auditor start
五、安装与配置代理节点 代理服务器接受请求并查找账户、容器或对象的位置最后将请求路由到正确的位置。代理服务器同样处理APIs请求。你可以修改proxy-server.conf文件启用帐号管理。
注意:建议所有的命令使用root帐号操作。
1. 安装swift-proxy服务:
# yum install openstack-swift-proxy memcached 2. 创建自签名证书:
# cd /etc/swift
# openssl req -new -x509 -nodes -out cert.crt -keyout cert.key 3. 修改memcached监听的端口。编辑/etc/memcached.conf文件:
将 -l 127.0.0.1 改变为 -l <代理服务器IP> 4. 重启memcached服务:
# service memcached restart 5. 使用openstack-config命令设置swift代理配置文件的keystone管理标识:
# openstack-config –set /etc/swift/proxy-server.conf filter:authtoken admin_token $ADMIN_TOKEN
# openstack-config –set /etc/swift/proxy-server.conf filter:authtoken auth_token $ADMIN_TOKEN 6. 创建/etc/swift/proxy-server.conf
- [DEFAULT]
- bind_port = 8888
- user = <user>
- [pipeline:main]
- pipeline = catch_errors healthcheck cache authtoken keystone proxy-server
- [app:proxy-server]
- use = egg:swift#proxy
- account_autocreate = true
- [filter:keystone]
- paste.filter_factory = keystone.middleware.swift_auth:filter_factory
- operator_roles = admin, swiftoperator
- [filter:authtoken]
- paste.filter_factory = keystone.middleware.auth_token:filter_factory
- # Delaying the auth decision is required to support token-less
- # usage for anonymous referrers (‘.r:*’).
- delay_auth_decision = true
- service_port = 5000
- service_host = 127.0.0.1
- auth_port = 35357
- auth_host = 127.0.0.1
- auth_token = 012345SECRET99TOKEN012345
- admin_token = 012345SECRET99TOKEN012345
- [filter:cache]
- use = egg:swift#memcache
- set log_name = cache
- [filter:catch_errors]
- use = egg:swift#catch_errors
- [filter:healthcheck]
- use = egg:swift#healthcheck
7. 创建账户,容器以及对象环。
命令第一个参数18代表2^18(2的幂),表示定义分区的大小,该值大小取决于你希望整个环使用存储的总大小;3代表每个对象备份的数量;最后一个数值表示分区移动的间隔(小时)。
# cd /etc/swift
# swift-ring-builder account.builder create 18 3 1
# swift-ring-builder container.builder create 18 3 1
# swift-ring-builder object.builder create 18 3 1 8. 为每个节点的存储设备添加条目至环:
# swift-ring-builder account.builder add z<ZONE>-<STORAGE_LOCAL_NET_IP>:6002/<DEVICE> 100
# swift-ring-builder container.builder add z<ZONE>-<STORAGE_LOCAL_NET_IP_1>:6001/<DEVICE> 100
# swift-ring-builder object.builder add z<ZONE>-<STORAGE_LOCAL_NET_IP_1>:6000/<DEVICE> 100 例如,如果你在IP 10.0.0.1存储节点上在Zone 1(区域1)中设置分区。挂载点是/srv/node/sdb1,且在rsyncd.conf文件中是/srv/node/,设备为sdb1。命令如下:
swift-ring-builder account.builder add z1-10.0.0.1:6002/sdb1 100
swift-ring-builder container.builder add z1-10.0.0.1:6001/sdb1 100
swift-ring-builder object.builder add z1-10.0.0.1:6000/sdb1 100 注意:假设5个区域中每个区域有一个节点,ZONE从1开始并通过添加额外节点增加该数值。
9. 验证ring内容:
swift-ring-builder account.builder
swift-ring-builder container.builder
swift-ring-builder object.builder 10. 调整rings:
swift-ring-builder account.builder rebalance
swift-ring-builder container.builder rebalance
swift-ring-builder object.builder rebalance 注意:这里会花费一些时间。
11. 拷贝account.ring.gz, container.ring.gz, object.ring.gz到每个代理与存储节的/etc/swift目录下。
12. 确保所有的配置文件所属者为swift:
# chown -R swift:swift /etc/swift 13. 开启Proxy服务:
# swift-init proxy start 配置OpenStack对象存储:
swift-init main start
swift-init rest start
六、安装验证 1. 运行swift命令,使用$ export ADMINPASS=secretword定义全局变量。
$ swift -V 2 -A http://<AUTH_HOSTNAME>:5000/v2.0 -U adminUser:admin -K 012345SECRET99TOKEN012345 stat 2. 获得X-Storage-Url 与 X-Auth-Token:
$ curl -k -v -H ‘X-Storage-User: adminUser:admin’ -H ‘X-Storage-Pass:$ADMINPASS’http://<AUTH_HOSTNAME>:5000/auth/v1.0 3. 检查账户:
$ curl -k -v -H ‘X-Auth-Token: <token-from-x-auth-token-above>’ <url-from-xstorage-url-above> 4. 使用swift上传一个名称为gigfile[1-2].tgz的文件至名为myfiles的容器:
$ swift -A http://<AUTH_HOSTNAME>:5000/v2.0 -U adminUser:admin -K $ADMINPASS upload myfiles bigfile1.tgz
$ swift -A http://<AUTH_HOSTNAME>:5000/v2.0 -U adminUser:admin -K $ADMINPASS upload myfiles bigfile2.tgz 5. 使用swift下载所有的文件:
$ swift -A http://<AUTH_HOSTNAME>:5000/v2.0 -U adminUser:admin -K $ADMINPASS download myfiles 排错:如果你遇到问题,可以查看/var/log/syslog。