随着“网络”一词的不断革新,微格式(microformat)是前进中重要的一步,因为它提供了一种机制能嵌入“聪明的数据”到网页中,并且易于内容提供者来实现。简单的说,微格式是规定了如何增加结构化数据到网页中,且不用修改原网页。这一节将主要介绍微格式,并且深入一些实例将用到XFN(XHTML Friends Network),geo, hRecipe 以及 hReview等微格式。特别的,我们将从博客链接中挖掘人的关系,从网页中抽取坐标,从foodnetwork.com中解析菜单,并且分析对这些菜单的评论。本章中示例代码的实现没有处理全部的解析细节,但足够能将你领上道了。以微格式如geo或hRecipe来标记数据被称作社会化数据,它是令人感兴趣的,且社会化数据将不断增加。在写这本书的时候,几乎有一半的网页开发页报告有用到微格式,microformats.org社区刚刚庆祝了它的5岁生日。google报告有94%概率,富摘要信息(Google在搜索结果里引入的一种新的网站信息显示方式)中包含了微格式,如果google宣传了这点,我们将看到微格式重要的增长;事实上,通过ReadWriteWeb,google想要看到50%的网页包含了某种形式的语义标注,并且鼓励公司通过奖励的形式来支持这一动机。不管怎么说,你将看到更多的微格式,如果你关心网络的话。让我们进入正题吧。
XFN和朋友关系
语义网的狂热者预言像FOAF(friend of a friend --一种实体论描述人与人之间的关系,活动和活动之间的关系)这样的技术可能有一天会成为催化剂,促使很多社交网络联合起来对抗如Facebook这样的平台。虽然这些所谓的语义网技术如FOAF目前还达不到这点,但也不用太惊讶。如果你知道一些关于网络的短暂历史,那么你就会认识到这个革新是不容易的,因为网络极其分散的性质让它很难一蹴而就(参见第10章),然而,变化正在持续的,稳固的,向前进化着。微格式的出现就是为填补网页上“智能数据”的空白,它是一个很好的示范带给已有的技术以规范的标准。在这种特定情况下,它拉近了传统网络(基于易于人类阅读的HTML4.01)和语议网络(更加友好,易于机器解释)的距离。
微格式的好处在于,它提供了一种方法去嵌入这样的数据:社交网络,日程,摘要,书签;并且是反向兼容的。微格式的生态系统是多种多样的,如geo就发展得很快,并随着搜索引擎,社交媒体网站,博客平台而大受欢迎,而其它微格式则发展缓慢。当正写这本书的时候,重要的微格式开发正在进行中,包括google宣称他们在宣摘要信息中支持hRecipe.表2-1提供了一个总结对一些受欢迎的微格式。更多的示例请看http://microformats.org/wiki/examples-in-the-wild
表2-1, 一些受欢迎的技术云去嵌入结构化数据到网页中
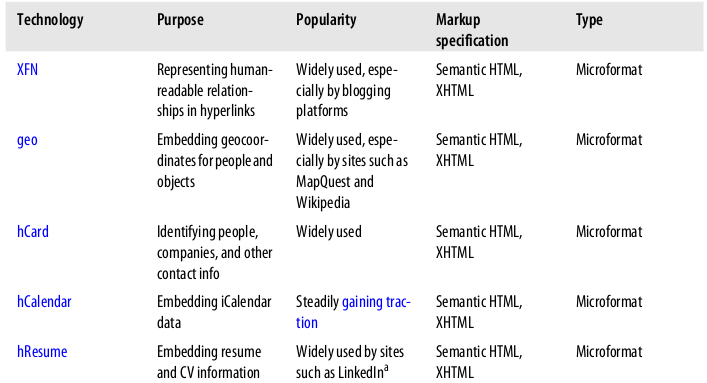
还有其他很多微格式你可能会碰到,但是一个好方法是,认准池塘中最大的那条鱼,如Google, Yahoo!, 以及Facebook.越多的人用到微格式,它就越可能成功,越对数据挖掘有用。
通过XFN导出社交联系
随着一点梗概关于微格式是如何适应整个网络空间,下面让我们转向一个操作性的XFN(可能是目前你所遇到的最受欢迎的微格式)程序。如你所知,XFN是一种方式,来标识与他人之间的朋友关系,以在其他标签中加入rel属性。XFN常用在博客中,特别是博客链接插件中,像WordPress提供的那样。考虑如下的HTML内容,如示例2-1, 这可能会出现在博客的友链中。
示例2-1,XFN标注示例
- <div>
- <a href="http://example.org/matthew" rel="me">Matthew</a>
- <a href="http://example.com/users/jc" rel="friend met">J.C.</a>
- <a href="http://example.com/users/abe" rel="friend met co-worker">Abe</a>
- <a href="http://example.net/~baseeret" rel="spouse met">Baseeret</a>
- <a href="http://example.net/~lindsaybelle" rel="child met">Lindsay Belle</a>
- </div>
从以上内容的rel标签,可以很明显的看出这些人之间的关系。名叫做Matthew的家伙,有一帮朋友,一位妻子,一个小孩,他和这些朋友中的一个是同事,他在日常生活中和大家见面(这情况在网上也许不会发生)。除去规范的语法外,这就是XFN的全部内容。好消息是,虽然它非常简单,但在大规模情形下,它非常有用,由于它是结构化的数据。除非你碰到一些数据严重的过时--如两个最好的朋友变成了敌人,而忘记了更新他们的博客链接--XFN给出了非常准备的信息关于两个人之间的联系。已知大部分博客平台支持XFN,有很多的信息可以去发现。坏消息是,XFN只能告诉你这些信息,如果要得到更多的信息,需要借助其它的微格式。
让我们来看一个简单的获取XFN数据的例子,它类似于rubhub(http://rubhub.com/,一个社会化的搜索引擎,它爬取和索引大量的网站信息通过XFN)提供的服务,你可能想看一下在线的XFN工具在进入下一节之前。
一个宽度优先的XFN数据爬虫
让我们通过XFN获取社交数据, 并以此建立一个社交图谱。已知XFN可以嵌入任何可信的网站,坏消息是我们要做一些网站爬取工作。好消息是,虽然很繁琐,但BeautifulSoup包帮你最小化了这些麻烦。示例2-2的代码涉及到Ajaxian( 一个很受欢迎的博客关于现代化的网站开发),作为图的基础。在运行它之前请用easy_install安装BeautifulSoup.
示例2-2,从网页中爬取XFN内容(microformats__xfn_scrape.py)
- # -*- coding: utf-8 -*-
- import sys
- import urllib2
- import HTMLParser
- from BeautifulSoup import BeautifulSoup
- # Try http://ajaxian.com/
- URL = sys.argv[1]
- XFN_TAGS = set([
- 'colleague',
- 'sweetheart',
- 'parent',
- 'co-resident',
- 'co-worker',
- 'muse',
- 'neighbor',
- 'sibling',
- 'kin',
- 'child',
- 'date',
- 'spouse',
- 'me',
- 'acquaintance',
- 'met',
- 'crush',
- 'contact',
- 'friend',
- ])
- try:
- page = urllib2.urlopen(URL)
- except urllib2.URLError:
- print 'Failed to fetch ' + item
- try:
- soup = BeautifulSoup(page)
- except HTMLParser.HTMLParseError:
- print 'Failed to parse ' + item
- anchorTags = soup.findAll('a')
- for a in anchorTags:
- if a.has_key('rel'):
- if len(set(a['rel'].split()) & XFN_TAGS) > 0:
- tags = a['rel'].split()
- print a.contents[0], a['href'], tags
传入一个URL(包含XFN)给这个脚本,它会返回名称,关系类型,以及指向其朋友的url,如下所示输出:
- Dion Almaer http://www.almaer.com/blog/ [u'me']
- Ben Galbraith http://weblogs.java.net/blog/javaben/ [u'co-worker']
- Rey Bango http://reybango.com/ [u'friend']
- Michael Mahemoff http://softwareas.com/ [u'friend']
- Chris Cornutt http://blog.phpdeveloper.org/ [u'friend']
- Rob Sanheim http://www.robsanheim.com/ [u'friend']
- Dietrich Kappe http://blogs.pathf.com/agileajax/ [u'friend']
- Chris Heilmann http://wait-till-i.com/ [u'friend']
- Brad Neuberg http://codinginparadise.org/about/ [u'friend']
假如这些URL中包含XFN或其它有用的信息,我们可以直接跟踪这些链接,系统的建立更全的社交信息图谱。这种方法就是下一个示例要用到的:以宽度优先的方式的建立图谱,如示例2-3的伪代码所示。
- Create an empty graph
- Create an empty queue to keep track of nodes that need to be processed
- Add the starting point to the graph as the root node
- Add the root node to a queue for processing
- Repeat until some maximum depth is reached or the queue is empty:
- Remove a node from the queue
- For each of the node's neighbors:
- If the neighbor hasn't already been processed:
- Add it to the queue
- Add it to the graph
- Create an edge in the graph that connects the node and its neighbor
注意用这种方法创建的图会自动建立双向的边(如果这样的边存在的话),而不用任何的额外操作,以此来发现相互的朋友很有用。示例2-4是示例2-2的改进版本,它通过跟踪XFN中的超链接来建立NetworkX图。运行示例代码,即使仅为2的深度也能得到一张相当大的图,这取决于朋友网络中XFN的受欢迎程度。同时建立一张图片,观察它,并在它上面运行各种图的度量(见图2-1)。
- # -*- coding: utf-8 -*-
- import sys
- import os
- import urllib2
- from BeautifulSoup import BeautifulSoup
- import HTMLParser
- import networkx as nx
- ROOT_URL = sys.argv[1]
- if len(sys.argv) > 2:
- MAX_DEPTH = int(sys.argv[2])
- else:
- MAX_DEPTH = 1
- XFN_TAGS = set([
- 'colleague',
- 'sweetheart',
- 'parent',
- 'co-resident',
- 'co-worker',
- 'muse',
- 'neighbor',
- 'sibling',
- 'kin',
- 'child',
- 'date',
- 'spouse',
- 'me',
- 'acquaintance',
- 'met',
- 'crush',
- 'contact',
- 'friend',
- ])
- OUT = "graph.dot"
- depth = 0
- g = nx.DiGraph()
- next_queue = [ROOT_URL]
- while depth < MAX_DEPTH:
- depth += 1
- (queue, next_queue) = (next_queue, [])
- for item in queue:
- try:
- page = urllib2.urlopen(item)
- except urllib2.URLError:
- print 'Failed to fetch ' + item
- continue
- try:
- soup = BeautifulSoup(page)
- except HTMLParser.HTMLParseError:
- print 'Failed to parse ' + item
- continue
- anchorTags = soup.findAll('a')
- if not g.has_node(item):
- g.add_node(item)
- for a in anchorTags:
- if a.has_key('rel'):
- if len(set(a['rel'].split()) & XFN_TAGS) > 0:
- friend_url = a['href']
- g.add_edge(item, friend_url)
- g[item][friend_url]['label'] = a['rel'].encode('utf-8')
- g.node[friend_url]['label'] = a.contents[0].encode('utf-8')
- next_queue.append(friend_url)
- # Further analysis of the graph could be accomplished here
- if not os.path.isdir('out'):
- os.mkdir('out')
- try:
- nx.drawing.write_dot(g, os.path.join('out', OUT))
- except ImportError, e:
- # Help for Windows users:
- # Not a general purpose method, but representative of
- # the same output write_dot would provide for this graph
- # if installed and easy to implement
- dot = []
- for (n1, n2) in g.edges():
- dot.append('"%s" [label="%s"]' % (n2, g.node[n2]['label']))
- dot.append('"%s" -> "%s" [label="%s"]' % (n1, n2, g[n1][n2]['label']))
- f = open(os.path.join('out', OUT), 'w')
- f.write('''''strict digraph {
- %s
- }''' % (';\n'.join(dot), ))
- f.close()
- # *nix users could produce an image file with a good layout
- # as follows from a terminal:
- # $ circo -Tpng -Ograph graph.dot
- # Windows users could use the same options with circo.exe
- # or use the GVedit desktop application

图2-1,Ajaxian网站XFN数据的双向图,注意在点“http://ajaxian.com/"和点"Dion Almaer"的边“Me"暗示Dion Almaer拥有这个博客。
尽管很简单,但这个图很有趣。它连接了八个点,以叫做“Dion Almaer"的人为中心点。如果再爬深一层或更多层,将在图中引入更多的结点来连接更多的人。单从这个图中,是不清楚Dion 和 Ben Galbraith 是否有更亲密的关系比起其他人来,因为"同事(Co-worker)"和"朋友(Friend)"关系的不同,但我们可以去爬取Ben的XFN数据,从中取得“同事”关系的数据,再爬取其同事的“同事”关系数据,从而建立一个谁和谁一起工作的社交网络。见第6章,挖掘同学和同事关系。
宽度优先技术的简要分析
我不想中断主题来花很长时间分析这项技术,但由于这个示例是本书的第一个严格意义上的算法,不是最后一个,因此有必要仔细去测验一下它。一般来说有两个标准去测验一个算法:效率和有效性,或者说,性能和质量。
一般的算法性能分析牵涉到它的最坏情况下时间和空间复杂度--换句话说就是,执行程序要发的时间,执行时占用的内存空间。我们采用的宽度优先方法在本质上是宽度优先搜索,虽然我们没有特别的去搜索什么,因为没有必要除了去扩展图到最大的深度或达到我们需要的结点。如果我们搜索一些特定的东西而不是只爬取链接,这就被认为是真正的宽度优先搜索。事实上,所有的搜索都有一些既定的标准,由于有限的资源的限制。因此宽度优先搜索的一种变异称作有边的宽度优先搜索,它引入了一个深度的限制,如我们所做的那样。
对于宽度优先搜索(或宽度优先爬取),时间和空间的复杂度在最坏情况是b^d,b是图中的分支因子,d是深度。如果你在纸上草拟一个示例,考虑一下它,这会很有意义。如果图中每个结点有5个邻居,你只想要1的深度,最终你将得到6个结点, 即根结点和它的五个邻居。如果所有的这五个邻居也有五个邻居,当你扩展到下一级时,就得到了总共31个结点,即根结点,根结点的五个邻居,以及根结点的每个邻居的五个邻居。这样的分析看起来很迂腐,但是在大数据的工程领域,能够利用已有的数据集做粗略的分析是更加重要了。表2-2提供了一概览关于b^d的增长
表2-2,图的结点数随着分支因子和深度增加而增加
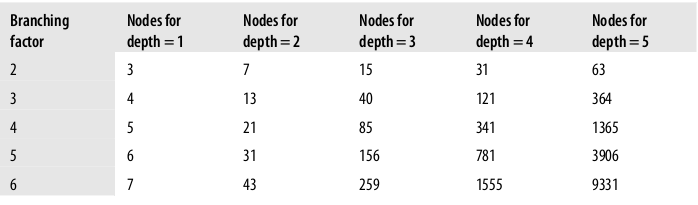
前面的讨论主要是关于算法理论上的复杂度,而最终要参考的度量是算法在实践中给定数据集上的性能。对代码大概的分析发现它的主要是I/O影响了其性能,因为大部分时间发在了等待urlopen返回数据来处理。在后面的一个示例, “多线程会话” 介绍和示范了用一个线程池来改善性能,以增加少量的复杂度为代价。
在这个分析中最后一项要考虑的是结果的质量。从质量分析的观点来看,由虚拟的视图可以看出这实际上是一个连接人的图谱。任务完成了吗?是的,但总是有改善的空间的。有一点要考虑的就是,结果中URL的细小差别会在图中多个结点中出现,虽然它们指向相同的内容。例如,如果涉及到Matthew的链接有http://example.com/~Matthew和http://www.example.com/~Matthew, 图谱中将出现两个不同的结点, 虽然它们可能指向相同的内容。幸运的是,XFN定义了一个rel="me"的特别值,来辨别可合并项。Google的社交图谱API就是用这种方法来连接用户的各种属性的,这里有许多的示例用rel="me"来允许用户在属性中添加外链。另外一问题(要小得多)就是URL的末尾是否有‘/’,大部分设计良好的网站会将一个转化为另一个,因此这就不成为问题了。
幸运的是,别人已经注意到了这个问题,并做了一些努力。SocialGraph Node Mapper(社交图谱结点映射)是一个有趣的开源项目,它可以标准化URL, 包括结尾的'/','www'是否出现等。它也可以辨别各种社交网站的不同URL指向同一个人, 如http://blog.example.com/Matthew和http://status.example.com?user=Matthew指向同一个人在某个社交网站上。
地标:A Common Thread for Just About Anything(不知这句什么意思。。。)
认为像geo, hRecipe这样的微格式对社交数据挖掘没有用而忽略他们是一个大错误。虽然单独的geo数据是没有用的,但它是很得要的将完成不同的数据集以相同的地理坐标联系在一起。地标数据是无所不在的,它们在社交数据结合上发挥了很多作用,因为将空间中的位置作为一个线索可以来聚类人们到一起。真实生活和网上生活的距离就被进一步接近,并且任何的社交化数据都与现实中的个体相连。例如,它可能是相当可怕的,你可能知道一个人她在哪里住,她在家做什么食物,甚至这些菜谱是由什么组成的。这一节来过一些示例,查找,分析,可视化地理和菜单数据,很快你将想到要怎么用它们。
维基百科的文章 + 谷歌地图 = 路线图 ?
一个最简单的微格式去嵌入地理数据到网页中的是geo, 具体的表现是通过vCard(提供了一种方式来描述位置)的属性geo。有两种方式可以嵌入geo微格式, 示例2-5中的HTML小片段说明了以这两种技术来描述富兰克林--田纳西州最好的一个小镇。
示例2-5,简单的geo标注
- <!-- The multiple class approach -->
- <span style="display: none" class="geo">
- <span class="latitude">36.166</span>
- <span class="longitude">-86.784</span>
- </span>
- <!-- When used as one class, the separator must be a semicolon -->
- <span style="display: none" class="geo">36.166; -86.784</span>
示例2-6用一个简单的程序分析geo微格式从MapQuest Local页面,来展示如何从geo格式的内容中抽取坐标。
示例2-6从MapQuest Local中抽取geo数据(microformats__mapquest_geo.py)
- # -*- coding: utf-8 -*-
- import sys
- import urllib2
- from BeautifulSoup import BeautifulSoup
- import HTMLParser
- # Pass in a URL such as http://local.mapquest.com/franklin-tn
- url = sys.argv[1]
- try:
- page = urllib2.urlopen(url)
- except urllib2.URLError, e:
- print 'Failed to fetch ' + url
- raise e
- exit()
- try:
- soup = BeautifulSoup(page)
- except HTMLParser.HTMLParseError:
- print 'Failed to parse ' + url
- exit()
- geoTag = soup.find(True, 'geo')
- if geoTag and len(geoTag) > 1:
- lat = geoTag.find(True, 'latitude').string
- lon = geoTag.find(True, 'longitude').string
- print 'Location is at', lat, lon
- elif geoTag and len(geoTag) == 1:
- (lat, lon) = geoTag.string.split(';')
- (lat, lon) = (lat.strip(), lon.strip())
- print 'Location is at', lat, lon
- else:
- print 'No location found'
用微格式的实现是巧妙然而在某各程度上意义深远:当一个正在读一篇文章关于一个地方如富兰克林,直觉的知道在地图上的一点指示这个镇的位置,一个机器就不能如此容易的得出这样的判断了,除非有特殊逻辑来针对各种样式匹配。但这样的页面抽取是非常脏的建议,且当你想要将所有的可能性都搞定的时候,你会发现你还是漏了一个。嵌入语义到网页中来标注非结构化数据,能够使机器人也能很轻易的明白,它消除了歧义,并降低了爬虫开发者的门槛。它是一个双赢的局面对消费者和生产者来说都是,希望能在这方面有更多创新。
绘制geo数据通过microform.at 和 google地图
在你从网页中发现有趣的geo数据的那一刻,每一件想要做的事也许就是可视化它。例如,考虑“美国国家公园列表”的维基百科文章,它显示了一个漂亮的国家公园的表格视图,并以geo格式来标了它们,但是它是不是更漂亮,去快速的将它们装载到一个交互工具中作可视化的观察?很好,microform.at就是一个极好的小的网络服务,它从给定的URL中抽取各种类型的微格式,并返回各种有用的格式的数据。它提供了各种选项去判断和交互同网页上的微格式数据,如图2-2

图2-2, http://microform.at的结果对于维基百科的文章“美国国家公园列表“
如果有得选, KML(Keyhole Markup Language)输出是最易于可视化geo数据的。你可以下载Google Earth然后在本地加载KML文件,或者输入一个URL指向KML数据的到google地图搜索框中,无需其它操作即可建立它。在microform.at显示的结果中,点击"KML"触发一个文件下载,此文件可以在Google Earth 中使用, 你也可以右键复制这个链接给Google Maps。图2-3显示了Google Maps的虚拟视图对于http://microform.at/?type=geo&url=http%3A%2F%2Fen.wikipedia.org%2Fwiki%2FList_of_U.S._na
tional_parks--前面提到的维基百科文章的KML结果,也就是基本的url:http://microform.at和类型以及查询的url参数。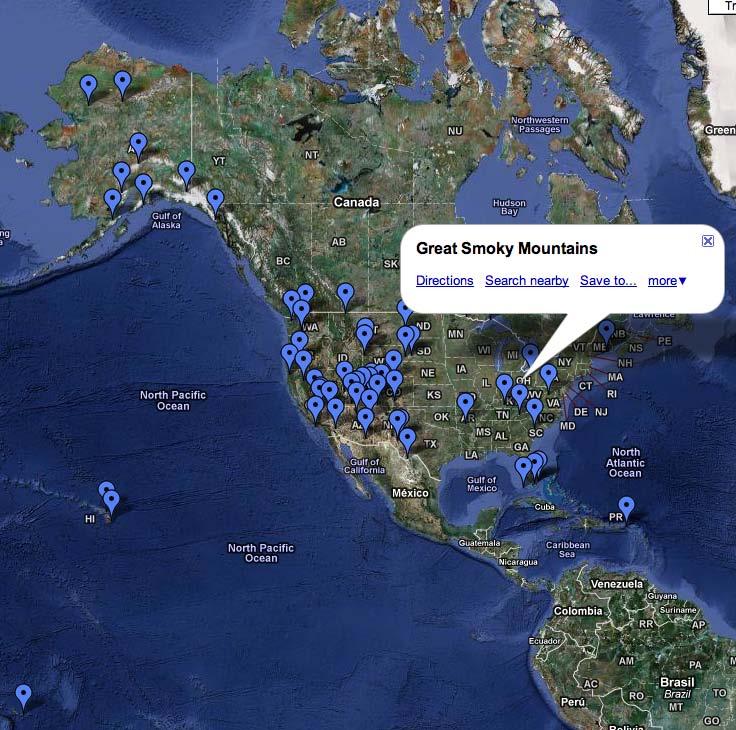
图2-3, Google Maps的结果显示所有美国的国家公园当传给它microform.at的KML数据
从包含语义标注(如geo数据)的维基百科文章中提取有用的数据,并可视化它, 这是一个很强大的分析能力,因为它可让我们很快洞悉重要的东西而只是做很少的工作。浏览器插件如Firefox Operator add-on 目标就是进一步降低这种劳动。在本节中只能讲这么多了,一个简洁的方法是发上一个小时左右的时间将本节中美国国家公园的数据同你的LinkedIn网络中联系人数据混合,从中你可能会发现怎么让下一次的出差更加有趣些。(见“从地理上了聚类你的网络“在第193页的例子,怎样通过使用k-means技术来查找类别并计算这些类别的中心点来获取和分析geo数据)
切分菜谱(为了健康)
由于google的富摘要信息的启动,将会有越来越多的微格式数据,许多的著名的美食网站做了很大的努力来暴露他们的菜单和评价通以hRecipe和hReview的形式。考虑这个潜在的可能性,一个虚拟的网上约会服务,它爬取博客和其它的社交网站,企图将配对人们去约会吃饭,某个人可能想要有权限查看特定的另一个的地理位置信息和菜单信息,这可能对增加第一次约会的成功机率有重大意义。人们能够被配对通过两个标准:一个人同另一个住的有多远;他们吃哪种类型的食物。例如,你可能会喜欢同肉食者约会吃饭而不是一个素食主义者。食物的偏好能够被用来增强商业创意。然而我们不会去创建一个新的网上数据服务,但我们想要激发你去创建它。
Food Network网站正完全的拥护以微格式来使整个网络更好,他暴露菜单信息以hRecipe并hReview格式来展现对菜单的评价。 这一节示范搜索引擎怎么从Food Network的菜单和评价中解析结构化数据以用来索引或分析。虽然我们不对菜单和评价中的纯文本数据作分析,或是持久的存储抽取的信息,后面的章节将会示范这些的如果你感兴趣的话。特别是,第3章介绍了CouchDB,一个很好的方法去存储和分享数据(和分析数据)--从包含微格式的网页中抽取的数据,第7章介绍一些基本的自然语言处理,你可以用来深入的分析评价数据。
示例2-6的一个改编版本来解析hRecipe格式的数据,如示例2-7.
示例2-7,从泰国菜中解析hRecipe数据(microformats__foodnetwork_hrecipe.py)
- # -*- coding: utf-8 -*-
- import sys
- import urllib2
- import json
- import HTMLParser
- import BeautifulSoup
- # Pass in a URL such as
- # http://www.foodnetwork.com/recipes/alton-brown/pad-thai-recipe/index.html
- url = sys.argv[1]
- # Parse out some of the pertinent information for a recipe
- # See http://microformats.org/wiki/hrecipe
- def parse_hrecipe(url):
- try:
- page = urllib2.urlopen(url)
- except urllib2.URLError, e:
- print 'Failed to fetch ' + url
- raise e
- try:
- soup = BeautifulSoup.BeautifulSoup(page)
- except HTMLParser.HTMLParseError, e:
- print 'Failed to parse ' + url
- raise e
- hrecipe = soup.find(True, 'hrecipe')
- if hrecipe and len(hrecipe) > 1:
- fn = hrecipe.find(True, 'fn').string
- author = hrecipe.find(True, 'author').find(text=True)
- ingredients = [i.string
- for i in hrecipe.findAll(True, 'ingredient')
- if i.string is not None]
- instructions = []
- for i in hrecipe.find(True, 'instructions'):
- if type(i) == BeautifulSoup.Tag:
- s = ''.join(i.findAll(text=True)).strip()
- elif type(i) == BeautifulSoup.NavigableString:
- s = i.string.strip()
- else:
- continue
- if s != '':
- instructions += [s]
- return {
- 'name': fn,
- 'author': author,
- 'ingredients': ingredients,
- 'instructions': instructions,
- }
- else:
- return {}
- recipe = parse_hrecipe(url)
- print json.dumps(recipe, indent=4)
用一个示例URL,如Alton Brown’s acclaimed Pad Thai recipe(奥尔顿受欢迎的泰国菜),你应该会得到如示例2-8所示的结果。
示例2-8, 示例2-7中泰国菜的解析结果
- {
- "instructions": [
- "Place the tamarind paste in the boiling water and set aside ...",
- "Combine the fish sauce, palm sugar, and rice wine vinegar in ...",
- "Place the rice stick noodles in a mixing bowl and cover with ...",
- "Press the tamarind paste through a fine mesh strainer and add ...",
- "Place a wok over high heat. Once hot, add 1 tablespoon of the ...",
- "If necessary, add some more peanut oil to the pan and heat until ..."
- ],
- "ingredients": [
- "1-ounce tamarind paste",
- "3/4 cup boiling water",
- "2 tablespoons fish sauce",
- "2 tablespoons palm sugar",
- "1 tablespoon rice wine vinegar",
- "4 ounces rice stick noodles",
- "6 ounces Marinated Tofu, recipe follows",
- "1 to 2 tablespoons peanut oil",
- "1 cup chopped scallions, divided",
- "2 teaspoons minced garlic",
- "2 whole eggs, beaten",
- "2 teaspoons salted cabbage",
- "1 tablespoon dried shrimp",
- "3 ounces bean sprouts, divided",
- "1/2 cup roasted salted peanuts, chopped, divided",
- "Freshly ground dried red chile peppers, to taste",
- "1 lime, cut into wedges"
- ],
- "name": "Pad Thai",
- "author": "Recipe courtesy Alton Brown, 2005"
- }
收集餐馆的评价
这一节结束我们对微格式的研究。Yelp的一个很受欢迎的服务,它用到了hReview,因此顾客留下的关于餐馆的评价是被暴露的。示例2-9示范了怎么抽取hReview信息从Yelp网页中。一个示例URL在代码中,它代表了一个泰国餐馆如果你有机会去的话一定不想错过的。
示例2-9,从泰国菜单中解析hReview数据(microformats__yelp_hreview.py)
- # -*- coding: utf-8 -*-
- import sys
- import re
- import urllib2
- import json
- import HTMLParser
- from BeautifulSoup import BeautifulSoup
- # Pass in a URL that contains hReview info such as
- # http://www.yelp.com/biz/bangkok-golden-fort-washington-2
- url = sys.argv[1]
- # Parse out some of the pertinent information for a Yelp review
- # Unfortunately, the quality of hReview implementations varies
- # widely so your mileage may vary. This code is *not* a spec
- # parser by any stretch. See http://microformats.org/wiki/hreview
- def parse_hreviews(url):
- try:
- page = urllib2.urlopen(url)
- except urllib2.URLError, e:
- print 'Failed to fetch ' + url
- raise e
- try:
- soup = BeautifulSoup(page)
- except HTMLParser.HTMLParseError, e:
- print 'Failed to parse ' + url
- raise e
- hreviews = soup.findAll(True, 'hreview')
- all_hreviews = []
- for hreview in hreviews:
- if hreview and len(hreview) > 1:
- # As of 1 Jan 2010, Yelp does not implement reviewer as an hCard,
- # per the spec
- reviewer = hreview.find(True, 'reviewer').text
- dtreviewed = hreview.find(True, 'dtreviewed').text
- rating = hreview.find(True, 'rating').find(True, 'value-title')['title']
- description = hreview.find(True, 'description').text
- item = hreview.find(True, 'item').text
- all_hreviews.append({
- 'reviewer': reviewer,
- 'dtreviewed': dtreviewed,
- 'rating': rating,
- 'description': description,
- })
- return all_hreviews
- reviews = parse_hreviews(url)
- # Do something interesting like plot out reviews over time
- # or mine the text in the descriptions...
- print json.dumps(reviews, indent=4)
截取的结果数据如示例2-10,它包括点评者,从hCard微格式结点中解析出来的。
示例2-10, 示例2-9的部分结果
- [
- {
- },
- "reviewer": "Nick L.",
- "description": "Probably the best Thai food in the metro area...",
- "dtreviewed": "4/27/2009",
- "rating": "5"
- ...truncated...
- ]
有无限的创新会发生,当你将极客和食物组合在一起,Cooking for Geeks这本书受欢迎就是个明证,也是O’Reilly出版的。随着美食网站改进并增加他们的API, 我们将在该领域有更多的创新。
总结
如果你无法记住本章中其它的东西,请记住微格式是一种方法来包装标注以暴露各种结构化数据,如菜单,联系人信息,人与人之间的关系。微格式有巨大的潜力因为它允许我们用已有的内容使得数据显式的且合适的达到预定的目标。期待到微格式在未来几个月中重大的增长。你也会吃惊于基于HTML5 microdata的创新随着HTML5市场份额的增加。如果你发现自己还有空余的时间,请看一下Google's social graph API, 它不同于Facebook的RDFa-based Open Graph protocol ,或是第9章中的Graph API,它包含XFN, FOAF和其它公开声明的联系的索引。
没有评论:
发表评论