How Google and Microsoft taught search to "understand" the Web
Inside the architecture of Google's Knowledge Graph and Microsoft's Satori.

Despite the massive amounts of computing power dedicated by search engine companies to crawling and indexing trillions of documents on the Internet, search engines still can't do what nearly any human can: tell the difference between a star, a 1970s TV show, and a Turkish alternative rock band. That’s because Web indexing has been based on the bare words found on webpages, not on what they mean.
Since the beginning, search engines have essentially matched strings of text, says Shashi Thakur, a technical lead for Google’s search team. “When you try to match strings, you don't get a sense of what those strings mean. We should have a connection to real-world knowledge of things and their properties and connections to other things.”
Making those connections is the reason for recent major changes within the search engines at Microsoft and Google. Microsoft’s Satori and Google’s Knowledge Graph both extract data from the unstructured information on webpages to create a structured database of the “nouns” of the Internet: people, places, things, and the relationships between them all. The changes aren't cosmetic; for Google, for example, this was the company's biggest retooling to search since rolling out "universal search" in 2007.
The efforts are in part a fruition of ideas put forward by a team from Yahoo Research in a 2009 paper called “A Web of Concepts,” in which the researchers outlined an approach to extracting conceptual information from the wider Web to create a more knowledge-driven approach to search. They defined three key elements to creating a true “web of concepts”:
- Information extraction: pulling structured data (addresses, phone numbers, prices, stock numbers and such) out of Web documents and associating it with an entity
- Linking: mapping the relationships between entities (connecting an actor to films he’s starred in and to other actors he has worked with)
- Analysis: discovering categorizing information about an entity from the content (such as the type of food a restaurant serves) or from sentiment data (such as whether the restaurant has positive reviews).
Google and Microsoft have just begun to tap into the power of that kind of knowledge. And their respective entity databases remain in their infancy. As of June 1, Satori had mapped over 400 million entities and Knowledge Graph had reached half a billion—a tiny fraction of the potential index of entities that the two search tools could amass.
In interviews with Ars, members of the teams at both Google and Microsoft walked us through the inner workings of Knowledge Graph and Satori. Additionally, we dug through the components of both search technologies to understand how they work, how they differ from the "old school" search, and what projects like these mean to the future of the Web.
Graphing the Web
Entity extraction is not exactly a new twist in search; Microsoft acquired language processing-based entity extraction technology when it bought FAST Search and Transfer back in 2008, for instance. What's new about what Google and Microsoft are doing is the sheer scope of the entity databases they plan to build, the relationships and actions they are exposing through search, and the underlying data store they are using to handle the massive number of objects and relationships within the milliseconds required to render a search result.
By any standard, Knowledge Graph and Satori are already huge databases—but they aren't really "databases" in the traditional sense. Rather than being based on relational or object database models, they are graph databases based on the same graph theory approach used by Facebook’s Open Graph to map relationships between its users and their various activities. Graph databases are based on entities (or “nodes”) and the mapped relationships (or "links") between them. They’re a good match for Web content, because in a way, the Web itself is a graph database—with its pages as nodes, and relationships represented by the hyperlinks connecting them.
Google’s Knowledge Graph derives from Freebase, a proprietary graph database acquired by Google in 2010 when it bought Metaweb. Google's Thakur, who is technical lead on Knowledge Graph, says that significant additional development has been done to get the database up to Google’s required capacity. Based on some of the architecture discussed by Google, Knowledge Graph may also rely on some batch processes powered by Google’s Pregel graph engine, the high-performance graph processing tool that Google developed to handle many of its Web indexing tasks—though Thakur declined to discuss those sorts of details.
Microsoft’s Satori (named after a Zen Buddhist term for enlightenment) is a graph-based repository that comes out of Microsoft Research’s Trinity graph database and computing platform. It uses the Resource Description Framework and the SPARQL query language, and it was designed to handle billions of RDF “triples” (or entities). For a sense of scale, the 2010 US Census in RDF form has about one billion triples.
Satori needs to be able to handle queries from Bing’s front-end—even ones that would require traversing potentially billions of nodes—in milliseconds. To make sure that it doesn't suffer from latency while waiting for calls to storage, Microsoft built the Trinity engine Satori is based on totally within memory, atop of a distributed memory-based storage layer. The result is a “memory cloud” based on a key-value store similar to Microsoft Azure’s distributed disk storage filesystem.
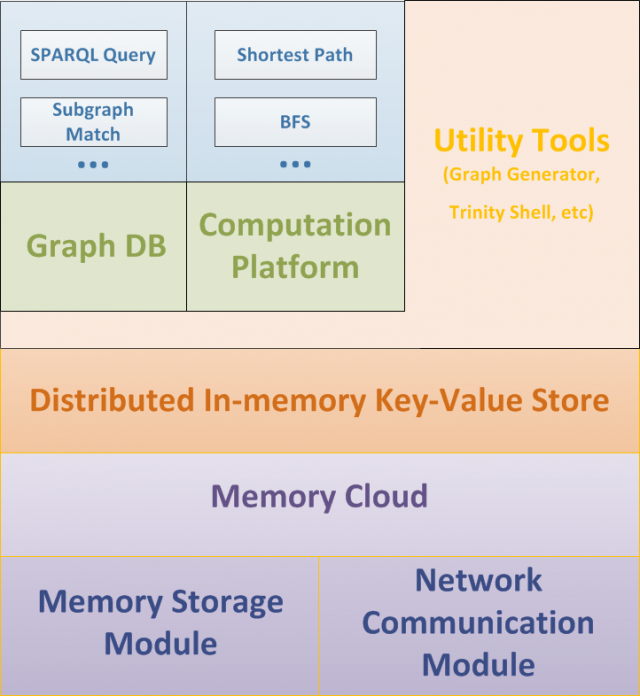
An overview of the system architecture of Microsoft Research's Trinity, the basis of Bing's Satori entity engine.
What's an entity, anyway?
The entities in both Knowledge Graph and Satori are essentially semantic data objects, each with a unique identifier, a collection of properties based on the attributes of the real-world topic they represent, and links representing the topic’s relationship to other entities. They also include actions that someone searching for that topic might want to take.
To get a better picture of what an entity looks like, let’s look at an example from Freebase.Freebase’s schema allows for a wide range of entity types, each with its own specific set of properties. These properties can be inherited from one type of entity to another, and entities can be linked to other entities for parts of their information. For example, a Blu-ray disc of a movie is a “film distribution medium,” which is a separate entity from the film itself. But it links back to the entity for the original film for information like the director and the cast:

Enlarge / A model view of Freebase's schema for "film distribution medium."
The schema for Google’s Knowledge Graph is based on the same principles, but with some significant changes to make it scale to Google’s needs. Thakur said that when Google purchased Metaweb, Freebase’s database had 12 million entities; Knowledge Graph now tracks 500 million entities and over 3.5 billion relationships between those entities. To ensure that the entities themselves didn’t become bloated with underused data and hinder the scaling-up of the Knowledge Graph, Google’s team threw out the user-defined schema from Freebase and turned to their most reliable gauge of the data users wanted: Google's search query stream.
“We have the luxury of having access to searches, which are like the zeitgeist,” Thakur said. “The search stream gives us a window into what people care about and what properties they look for.” The Knowledge Graph team processed Google’s stream of search data to prioritize the properties assigned to entities based on what users were most interested in—how tall buildings are, what movies an actor starred in, how many times a celebrity went to rehab.
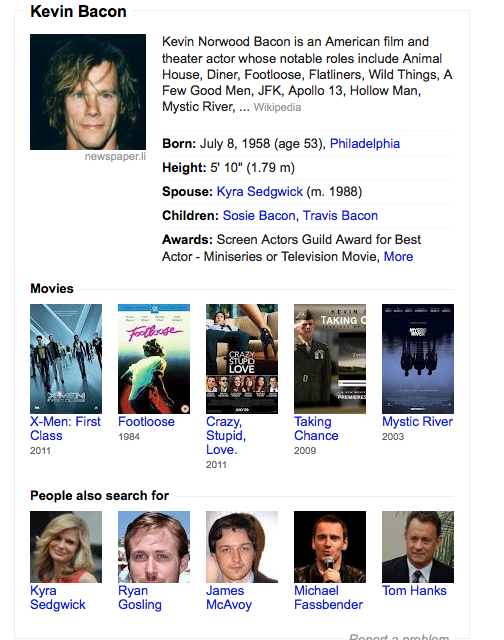
A view of Google Knowledge Graph's entity data on Kevin Bacon. Not all six degrees are shown.
“In the absence of that, creating a schema for a type is speculative and opportunistic,” Thakur explained. “You put your hands on some source of information, get some data back into the Knowledge Graph, and who knows if people care about that or not.”
Microsoft has used its own search stream to help with modeling, but with a different goal. The query processing was more focused on mining searches for actions rather than for specific types of properties for which people searched. In a paper published in April, researchers from Microsoft Research’s Natural Language Processing group described the process of creating “Active Objects,” a set of dynamic actions that could be assigned as properties to certain types of entities.
“We took all the query logs for several months and had the machines break them down into types of actions,” Stefan Weitz, director of search at Microsoft, told Ars in an interview. “Then we took the top query types and started to figure out which were the most common tasks people were doing with search.”
When it came to bands, he said, those actions include buying music, finding lyrics, or getting tickets to a concert. For restaurants, the actions could include looking at a menu, showing reviews, or making a reservation.
But the data structure for each entity isn’t hard-wired in Satori. Every property for every entity is added by Satori itself as it discovers new related content and is “accreted over time,” Weitz said. That process happens as Satori processes crawled websites to do entity extraction.
Sucking the brains out of the Internet
Both Google and Microsoft have had plenty of experience in extracting content from webpages. Populating the Knowledge Graph and Satori entity databases starts in much the same way as Web indexing, with crawlers gathering the text from trillions of webpages.
Satori’s crawler discovers new objects within webpages; entities are created for them and added to the database. “The crawlers go through a page, parsing it, and [recognize] an object [and] say, 'this object is a 16-ounce bottle of Dasani Water,'” Weitz said. Using the data on the page, the crawler aggregates the water bottle's characteristics and moves on.
But all the information on that entity is rarely in one place. When crawlers find another page that contains an entity that Satori has already identified, they tag the page with that entity’s signature as part of the crawl; new characteristics Satori finds during later processing get aggregated into the original entity. “The beauty of machine learning is that if the crawler finds something on a page about an object that we didn't have in Satori, it can add it,” Weitz said.
As Satori processes the webpages identified as being related to an entity (using Microsoft Azure infrastructure for the offline processing), it goes through the content and pulls out additional characteristics, eventually building a model based on all the available data scattered across the Web. “So at the end of that—for example, with the Dasani bottle—we can say this bottle of Dasani water has 48 characteristics,” Weitz said. “And that helps us understand what kinds of actions we can take on those objects when they’re presented in search.”
Google’s extraction process also starts with its crawl of webpages. Thakur said that as Google’s search bots crawl through documents “there are text interpretations that happen” to determine the topic or topics of a page. As pages are indexed by Google’s huge keyword-based MapReduce jobs, they are also processed by natural language-based semantic tools (which may be where Google’s Pregel graph engine comes into play).
But neither Google nor Microsoft send their entity extractors out into the wild Web without some early training. Both had stores of data already on hand to “seed” their entity engines with some well-structured starter entities. In Google’s case, the Knowledge Graph team was able to begin with the 12 million entities that had already been put into Freebase by its user community, as well as by drawing on open sources of data such as the CIA World Fact Book and Wikipedia. Microsoft was more focused on providing objects that would best play into its Action Object model, so much of the initial attention was paid to product catalogs and e-commerce sites, according to Weitz.
With the backend database in place, the only question left was how to expose it to search users.
没有评论:
发表评论