How Google and Microsoft taught search to "understand" the Web
Inside the architecture of Google's Knowledge Graph and Microsoft's Satori.
The front-end
Microsoft and Google have exposed the knowledge stored in their entities in similar ways, though Microsoft has also added other interface items based on the processing of social graphs and other social media. On the surface, Google’s new engine appears to be more about getting answers to questions, while Microsoft’s new Bing front-end exposes entities in a way that is more suited to taking actions—or to making transactions.
Knowledge Graph presents itself within search in three ways. The first is as a contextual box that appears when you enter a search term with a wide range of possible contexts. In the past, if you did a Google search for “blowfish,” you’d get a jumble of results: for a shoe company, for the Blowfish encryption algorithm, and for sushi. But now the search also yields a box on the right-hand side of the search results window offering to show you the results for “pufferfish,” with a brief bit of information explaining its context.
Similarly, if you search for “kings” you’ll get a variety of hits—news of the hockey team (the LA Kings), the Wikipedia listing for the cancelled TV series, and the drinking game played with cards. You will also get a box that prompts you about results specifically for the TV series, the hockey ream, or the Sacramento Kings basketball team.
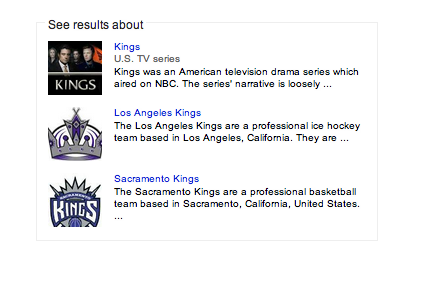
The Knowledge Graph contextual cues for the search "kings."
Drill down on the TV series and you’ll find a box with information on the show in the right side of the screen, along with links to the stars.
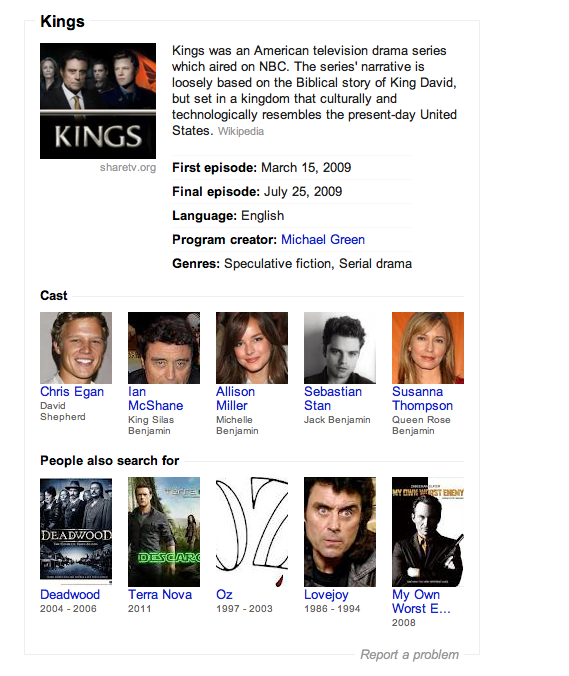
The entity data in Knowlege Graph for the cancelled TV series Kings, as displayed in Google Search's right column.
Thinking of pufferfish and hockey got me thinking about fish on ice, which inevitably led to a search on sushi. Here Google’s Knowledge Graph gets a bit more interactive. Initially, a search for sushi serves up results with a map of nearby sushi restaurants based on my location on the right side, and lists them on the left with their addresses, phone numbers, their Zagat review scores (Zagat being another source of entity data that Google has purchased), and links to Google reviews.

But then, as I mouse over the “>>” next to each of the results, other data on each restaurant is revealed: hours, a summary of the Zagat review, the location of the nearest bus stop, and a thumbnail view of the restaurant’s website. All this is data that gets stored as part of the entity for the restaurant in Knowledge Graph.

Microsoft
Then there’s Bing. Microsoft’s search engine presents its Satori-based structured data in a center panel of the screen, called “Snapshot.” This is where the Action Object interface comes into play, displaying the structured data associated with the entities brought up by the search.
At the same time, on the right hand side of the page, Bing is querying two other graphs using natural language processing. If you’re logged into Facebook, it hits up your own social graph for friends who may have expressed an interest or some expertise in the topic you’re searching on. Below that, Bing hits Twitter, Yelp, and other social sites, as well as blogs, to find people you don’t know but who might have some influence or expertise on the topic. These “social” searches aren’t related to Satori’s entities, but instead are driven by keyword matching.
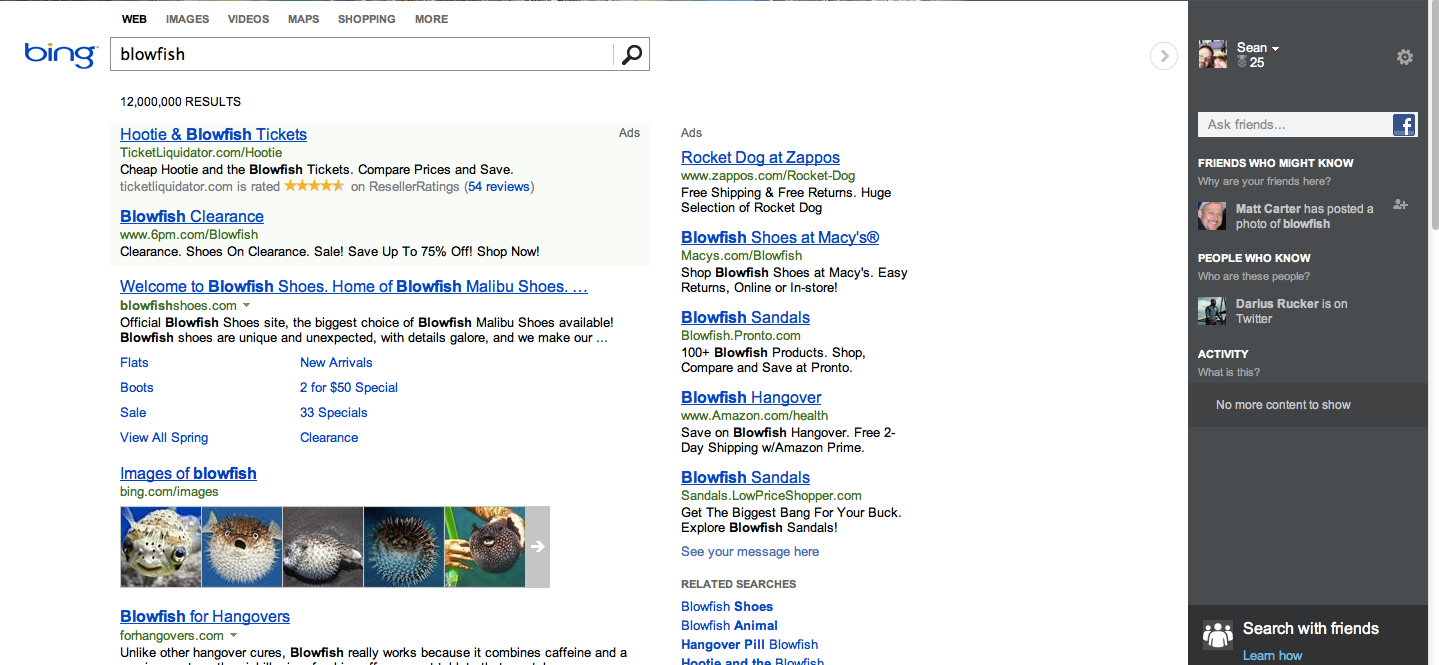
Enlarge / Apparently, the Bing Search team didn’t find a lot of user searches that had actions related to “blowfish” or “pufferfish” (and didn’t seed its entity base with Wikipedia). And Satori isn’t big on cancelled television series or hockey box scores, either.

Enlarge / But when you search for “sushi” on Bing, you get results that look a bit like Google’s—though with TripAdvisor and Yelp in the place of Zagat.

Enlarge / Bing digs down into several other review sites to get sentiment information, and exposes OpenTable as a link if a restaurant takes reservations. Hotels and other service locations get similar treatment.
Searching for the future
Despite having similar technology bases, Google and Microsoft's new results are colored mostly by how they chose to seed their data. Because they’ve been built largely around the most popular sorts of searches, both entity databases still contain plenty of holes.
Filling those holes is no small matter. The larger the semantic databases of Knowledge Graph and Satori become, the more they will potentially put a drag on the performance of search. Google already is pre-fetching a significant amount of Knowledge Graph results in cache to avoid a performance hit. And while Satori's technology base is designed to grow to up to 800 million entities and still be able to handle queries in 50 milliseconds, the Bing Satori store is already halfway to that number after just a few weeks of crawling the Web.
And the graphs aren't really even getting a full workout yet. Google and Microsoft are already exploiting their entity databases beyond their main search pages—Google has added Knowledge Graph to YouTube's topic search, for example, while Bing's shopping and travel sites are drawing on Satori's entities. But entity-based search is still in its earliest stages, because there's no way for search users to fully take advantage of the relationship mapping in these semantic data stores.
That's mostly because the natural language processing that makes it possible to extract entities hasn’t yet arrived at the search bar. “We want to focus more and more on handling English language formulation for searches,” said Thakur, “so someone could search for ‘volcanic eruptions in the 18th century’ or ‘Lady Gaga concerts in a warm outdoor location.’”
For now, there’s no way for Google or Microsoft to reliably parse those sorts of queries against entities’ properties. And Microsoft’s Weitz says that “people have been beaten down in search for so long, they’d never ask” those sorts of questions in the first place. Complex relational queries are the sorts of things that Bing and Google tend to push off to their more vertical search areas, like Bing’s shopping and travel search and Google’s Shopping and Flights.
And for now, Knowledge Graph and Satori are operating within a very defined linguistic space—they only work with content in US English. When other languages are added to the entity extraction language processing of the search engines, the number of entities and relationships they have to manage is bound to explode, both in terms of number and complexity. To truly "understand" the Web, Knowledge Graph and Satori are going to have to get a lot smarter. And they're bound to push the bounds of semantic processing and computing forward in the process, as bigger and bigger graphs of knowledge are shoved into memory.
没有评论:
发表评论